
Générative AI : une maturité technologique au service de l’impact

Statistiques AWS 2025 sur l’adoption de l’IA en France (90 % des entreprises déclarent une hausse de CA, 68 % des startups utilisent la GenAI).
Dès la session plénière d’ouverture, le ton est donné : l’IA générative est désormais largement adoptée par les entreprises françaises. Une étude présentée lors du keynote indique que 90 % des entreprises ayant déployé de l’IA générative observent une hausse de leur chiffre d’affaires, tandis que 68 % des startups françaises utilisent déjà la GenAI dans leurs produits ou services. Ces chiffres en forte progression (+26 % sur un an) témoignent de la montée en puissance de la GenAI dans tous les secteurs d’activité.
Concrètement, AWS a mis en avant plusieurs témoignages clients illustrant cette maturité. Par exemple, Safran, géant de l’aéronautique, a témoigné de son usage d’Amazon Bedrock pour l’analyse de documents techniques et la maintenance prédictive, avec à la clé 1 million d’euros d’économies en 18 mois. Safran a d’ailleurs annoncé un partenariat renforcé avec AWS pour déployer l’IA générative à grande échelle, dans des objectifs ambitieux comme la décarbonation de l’aviation et l’optimisation de la supply chain. Autre exemple parlant : Veolia associé à la startup française Mistral AI a montré comment l’IA aide à la détection de pannes industrielles, à la classification documentaire, et prépare de futurs assistants vocaux métier. Que ce soit Owkin (santé), Qonto (fintech) ou Poolside (outil pour développeurs), tous ces acteurs ont démontré des cas d’usage réels en production, bien loin des simples POC : la GenAI est devenue un atout opérationnel concret, du support aux techniciens de maintenance jusqu’à la lutte contre la fraude bancaire. L’IA leur permet d’améliorer l’expérience client, d’optimiser leurs opérations internes ou de dégager de nouveaux revenus. Après l’ère des simples chatbots de 2024, on voit clairement que 2025 est l’année des agents IA et des solutions génératives à forte valeur ajoutée en production, avec à la clé des ROI concrets et une intégration poussée dans les systèmes d’information existants.
Enfin, impossible de ne pas mentionner Mistral AI – fleuron de la French Tech dans les LLM – qui a profité du Summit pour annoncer la disponibilité de son modèle maison Pixtral Large sur Amazon Bedrock. C’est le premier modèle européen de ce type proposé en mode serverless entièrement géré sur AWS. Pour la communauté tech française, c’est un signal fort : nos innovations locales trouvent leur place dans l’écosystème cloud mondial. En tant qu’expert, je suis satisfait de voir AWS embrasser cette diversité de modèles et d’approches : cela ouvre la porte à davantage de choix stratégiques pour nos propres projets (selon les cas, on pourra opter pour un modèle AWS, Open Source, local ou autre, sans friction d’intégration).
L’essor des systèmes multi-agents : vers des IA collaboratives

Panel “De l’IA assistante à l’IA créatrice” avec Dust, Anthropic et Balderton sur les agents IA et le MAS.
Si l’IA générative atteint une certaine maturité, une nouvelle frontière s’ouvre déjà : celle des systèmes multi-agents (MAS). Plutôt que de s’appuyer sur un seul agent conversationnel, l’idée est d’orchestrer plusieurs agents intelligents qui collaborent pour accomplir des tâches complexes. Ce thème, qui fait écho aux expérimentations d’AutoGPT et consorts ces derniers temps, a été largement mis en avant au Summit.
Lors d’un panel intitulé “De l’IA Assistante à l’IA Créatrice : La Révolution des Agents”, des experts ont échangé sur cette révolution à venir. Aux côtés d’AWS, on retrouvait des acteurs phares du domaine comme Guillaume Princen (Head of EMEA d’Anthropic), Gabriel Hubert (CEO de Dust) et Zoé Mohl (Principal chez Balderton Capital). Ce panel a exploré l’évolution des IA conversationnelles vers des agents plus autonomes et proactifs, capables non seulement de répondre à des questions, mais aussi de prendre des initiatives, d’appeler d’autres services, voire de collaborer entre eux. Les intervenants ont souligné que pour s’attaquer à des tâches complexes, un seul agent IA ne suffit plus : il est souvent préférable d’orchestrer plusieurs agents spécialisés (on parle de Multi-Agent Systems ou MAS), chacun étant expert dans un domaine, et de les faire interagir pour atteindre un objectif commun. Tous partagent la vision d’un futur proche où des essaims d’agents spécialisés coopèrent pour résoudre des problèmes, un peu à la manière d’équipes humaines ou de microservices logiciels. En discutant avec mes pairs, je constate que cette idée séduit particulièrement les profils R&D – y compris chez Squad où nos travaux explorent déjà les architectures multi-agents. Il est enthousiasmant de voir nos intuitions confirmées par les tendances du marché.
Un exemple concret de cette approche multi-agents a été fourni par Qonto, la néo-banque française, qui a frappé fort en révélant avoir déployé pas moins de 200 agents IA en production pour détecter la fraude et automatiser des tâches financières du service PayLater (paiement différé) pour ses clients professionnels, ce qui a permis de prévenir 3 millions d’euros de fraude. Ce chiffre donne le vertige et prouve qu’on n’est plus dans l’expérimentation de labo : en coordonnant des centaines d’agents (certains surveillant des transactions, d’autres gérant des contrôles compliance, etc.), Qonto a atteint un niveau d’automatisation et de vigilance inédit dans son SI.
Plutôt que de reposer sur un unique modèle monolithique, Qonto a orchestré trois types d’agents complémentaires pour traiter chaque demande :
- Agents “Vision” – Ils utilisent le LLM Claude 3.7 d’Anthropic (via Amazon Bedrock) pour lire et extraire les informations des factures fournies par les clients (montant, date, fournisseur, etc.).
- Agents “Recherche” – Ils interrogent des sources externes et API publiques (Google via Serper, registre d’entreprises INPI, etc.) afin de vérifier les informations sur l’acheteur et le vendeur (existence de la société, solvabilité, risques éventuels), en s’appuyant sur les données extraites par l’Agent Vision.
- Agents “Analyse” – Ils exécutent du code de validation métier et croise les données (par exemple vérifier les historiques de paiement, la conformité réglementaire AML/KYC) pour décider si la transaction peut être approuvée ou non.
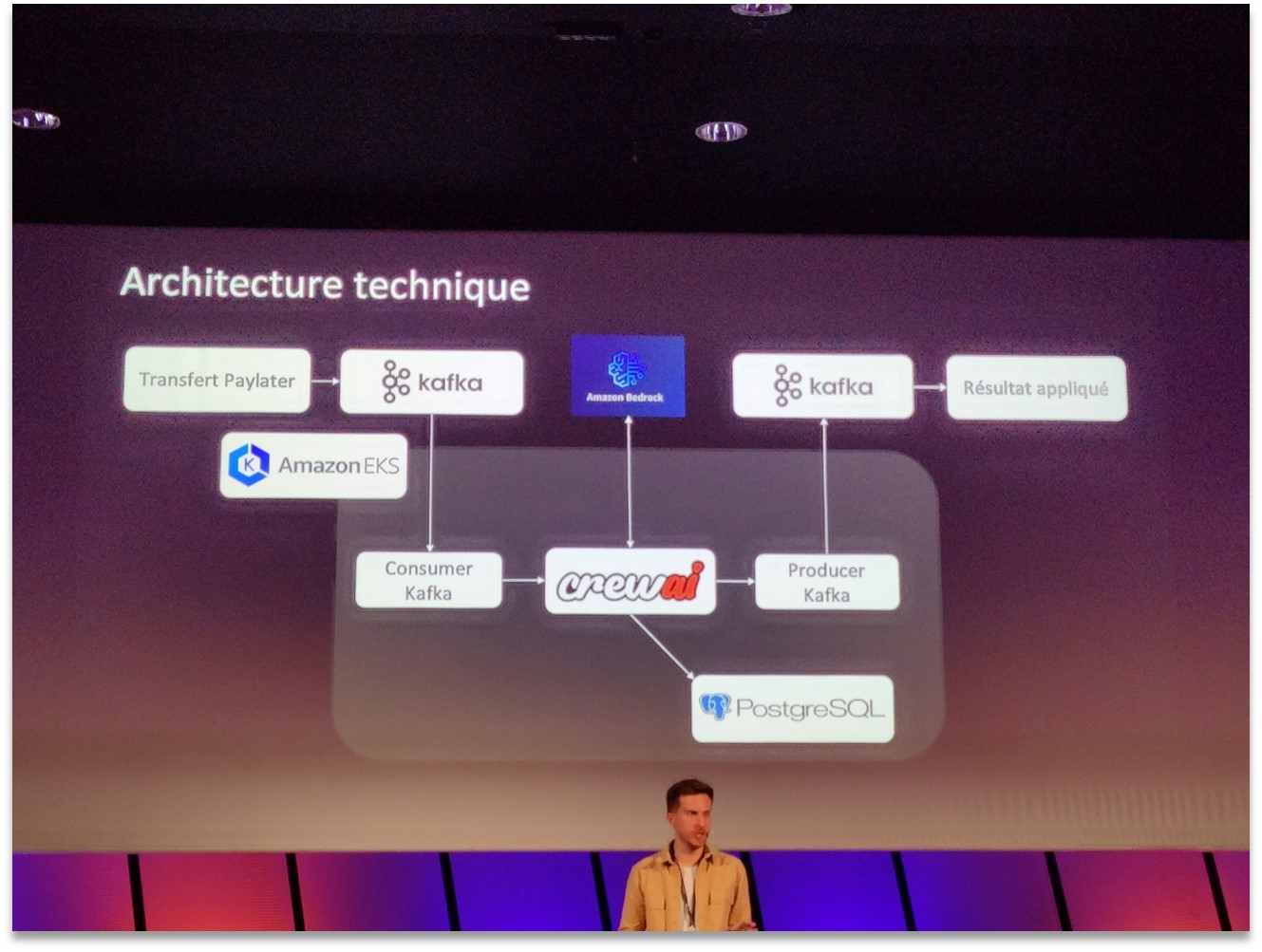
Architecture technique CrewAI chez Qonto pour le traitement du PayLater avec Kafka, PostgreSQL, EKS et Amazon Bedrock.
L’architecture présentée par Qonto (illustrée ci-dessus) s’appuie sur le framework open-source CrewAI pour orchestrer ces agents au sein de conteneurs sur Amazon EKS. Les événements de demande de financement (« Transfert PayLater ») sont publiés dans Kafka, consommés par le service CrewAI qui pilote les agents, lesquels peuvent stocker et lire des données dans une base PostgreSQL et faire appel aux modèles d’Amazon Bedrock. Une fois l’analyse terminée par les agents, le résultat (approbation ou refus du financement) est produit dans Kafka puis appliqué dans le système de transaction. Ce système multi-agents a permis à Qonto de réduire le temps de traitement d’une demande de 6 heures à moins de 5 minutes, d’automatiser 25 % des cas dès le déploiement (avec un objectif de 80 % sous peu), et ainsi de passer à l’échelle sans recruter massivement pour les vérifications manuelles. Pour les équipes DevOps, cet exemple démontre qu’avec la bonne architecture, la GenAI peut être intégrée de façon fiable dans des workflows métier critiques tout en restant scalable et maintenable.
De son côté, le géant du ciment Holcim a montré comment des agents alimentés en IA générative peuvent automatiser des processus métiers jusque-là manuels : par exemple, le traitement des factures a été accéléré de façon spectaculaire (90 % de réduction des traitements manuels grâce à l’IA). Même dans l’agriculture, un acteur comme Syngenta utilise la collaboration d’agents via Bedrock pour optimiser les rendements agricoles, avec +5 % de productivité sur certaines cultures – un gain énorme à l’échelle de ce secteur.
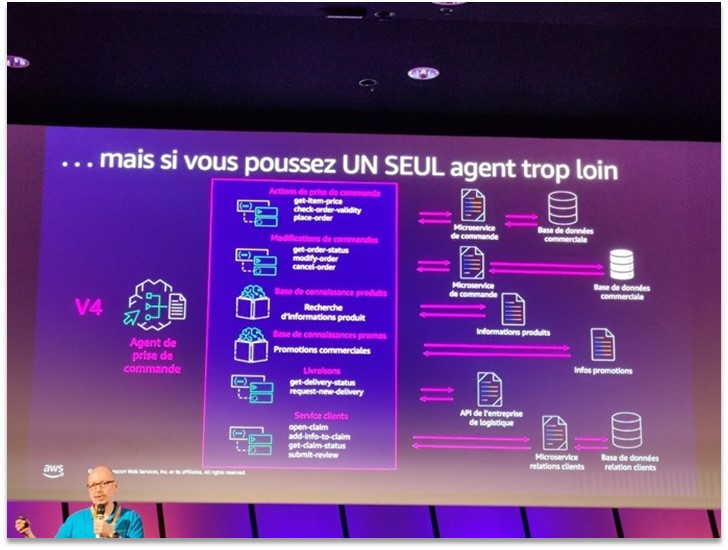
Problématique du “super agent” IA : lorsqu’un agent unique gère trop de cas d’usage, il devient lent, coûteux et imprécis. D’où l’intérêt des MAS.
Plus généralement, les discussions au Summit ont mis en garde contre le mythe du « super agent » capable de tout faire. Une slide parlante montrait qu’en voulant confier trop de responsabilités à un seul agent (par exemple gérer à lui seul l’intégralité d’un processus e-commerce, de la prise de commande au SAV), on obtient un agent lent, coûteux en ressources, et souvent imprécis. À l’inverse, en adoptant une approche modulaire multi-agents, on peut décomposer le problème en sous-tâches, optimiser chaque agent pour sa tâche spécifique, et ainsi obtenir une solution globale plus efficace. Ce principe d’architecture, qui rappelle le découpage en microservices, est en train de s’imposer comme une bonne pratique pour les applications d’IA avancées.
Cependant, cela pose aussi de nouveaux défis d’ingénierie – comment superviser et débugger une constellation d’agents ? comment éviter qu’un agent ne devienne malveillant ou inefficace ? Nous suivrons de près les retours d’expérience comme ceux de Qonto pour en tirer les bonnes pratiques.
Sécurité et gouvernance des LLM : des garde-fous indispensables

Résultat d’étude Gartner 2024 : 59 % des CIO estiment que les hallucinations des LLM sont le risque principal, devant la désinformation et la confidentialité.
Avec l’adoption massive de la GenAI, la sécurité et la fiabilité de ces systèmes sont devenues des préoccupations majeures. D’après une étude Gartner citée lors du Summit, la principale crainte des DSI concernant les LLM est le problème des hallucinations (59 % d’entre eux la citent comme risque n°1) – c’est-à-dire ces réponses inventées par le modèle pouvant causer des erreurs de décision. Viennent ensuite les risques de désinformation intentionnelle (48 %) et de confidentialité des données (44 %). Conscient de ces enjeux, AWS a dédié plusieurs sessions aux bonnes pratiques de sécurisation des applications d’IA générative.

Les trois piliers de la sécurité GenAI selon AWS : sécurisation des apps IA, usage d’agents pour la cybersécurité, protection contre les nouvelles menaces IA.
Une présentation instructive a notamment introduit les “trois piliers de la sécurité de l’IA générative” selon AWS, représentés par un tabouret à trois pieds (voir ci-dessus). Ces trois volets sont :
- Sécuriser les applications d’IA générative – s’assurer que nos chatbots, agents et autres applications basées sur des LLM ne deviennent pas des vecteurs d’attaques.
- Utiliser l’IA générative pour sécuriser l’environnement – se servir des modèles d’IA comme outils défensifs en cybersécurité.
- Se protéger contre les menaces émergentes liées à l’IA générative – anticiper et contrer les nouveaux types d’attaques rendues possibles par l’IA (deepfakes, usurpation via voix synthétique, etc.).
Le premier pilier concerne la protection de nos applications contre les vulnérabilités propres aux LLM. On pense par exemple au prompt injection (un utilisateur malveillant qui manipule les instructions du modèle), à la fuite d’informations sensibles dans les réponses de l’IA, ou encore au vol de modèle (exfiltration des poids d’un modèle entraîné). À ce sujet, les intervenants ont mentionné que l’OWASP travaille sur un Top 10 des risques spécifiques aux applications LLM, à l’instar du Top 10 classique pour les applications web.

OWASP Top 10 pour les applications LLM, avec mise en garde contre le prompt injection, la fuite de données, le vol de modèle, etc.
Parmi ces risques LLM énumérés (voir l’illustration ci-dessus), on retrouve notamment : LLM01 : Prompt Injection, LLM02 : Mauvaise gestion des sorties du modèle, LLM03 : Empoisonnement des données d’entraînement, LLM06 : Fuites d’informations sensibles, LLM09 : Surconfiance dans le modèle, ou encore LLM10 : Vol de modèle. En tant que DevSecOps, il est crucial d’intégrer dès la conception des gardes-fous (GuardRails) contre ces vulnérabilités : validation et filtrage des entrées/sorties du LLM, gestion du cycle de vie des secrets et clés API utilisés par le LLM, surveillance des appels pour détecter d’éventuels abus, etc. Le message est clair : une application GenAI doit être sécurisée avec la même rigueur qu’une application web critique, en adaptant nos outils et réflexes aux particularités des modèles de langage.
Le deuxième pilier met en lumière comment l’IA peut être un allié en cybersécurité. Un cas d’usage marquant présenté fut celui d’un agent IA de sécurité capable de répondre à des questions sur les vulnérabilités connues et d’assister les analystes SOC. En combinant un LLM avec des knowledge bases de sécurité, on peut accélérer l’analyse des incidents ou la réponse aux développeurs sur les failles. AWS a d’ailleurs montré comment construire rapidement un tel assistant via Amazon Bedrock.

Extrait de code Python démontrant l’implémentation d’un agent IA de sécurité interrogeant les CVE OWASP Top 10 via Amazon Bedrock.
Le code ci-dessus illustre la simplicité avec laquelle on peut implémenter un agent LLM outillé. En Python, on définit une fonction outillée (get_top10_cves) pour récupérer la liste des 10 principales failles (ici le Top 10 OWASP). On configure ensuite le client Bedrock pour qu’il utilise cette fonction “tools”, outil que le modèle pourra appeler lorsqu’on l’interroge. Résultat : en une trentaine de lignes, on dispose d’un assistant capable de fournir la liste des CVE critiques ou de détailler les failles les plus courantes, en s’appuyant sur un modèle hébergé par Bedrock. Ce type d’agent pourrait être intégré dans un chatbot interne, un outil de scan de code, ou tout autre système de sécurité pour augmenter la productivité des équipes techniques.
Enfin, le troisième pilier aborde les nouvelles menaces créées par l’IA elle-même. Il s’agit ici de se protéger des usages malveillants de la GenAI : des pirates qui utiliseraient des LLM pour automatiser le phishing ou générer du malware sophistiqué, la diffusion massive de désinformation par des bots IA, ou encore les attaques indirectes comme l’empoisonnement de modèles (pusher de mauvaises données pour fausser un modèle). Sur ce front, AWS recommande une veille technologique active et la mise en place de défenses spécifiques. Par exemple, des solutions commencent à émerger pour détecter les contenus synthétiques (deepfakes) ou pour tester les modèles via des Red Team IA. L’objectif est de ne pas se laisser distancer : tout comme les attaquants innovent avec l’IA, les défenseurs doivent intégrer l’IA dans leur arsenal et adapter leurs stratégies de sécurité. En somme, sécurité et IA doivent avancer main dans la main à l’ère de la GenAI.
Platform Engineering : toujours plus d’efficacité à grande échelle
Outre l’IA, le Summit a également fait la part belle au Platform Engineering et aux nouveautés facilitant la vie des équipes infra/DevOps. Un sujet a particulièrement retenu l’attention : le déploiement d’EKS en mode “Auto”.
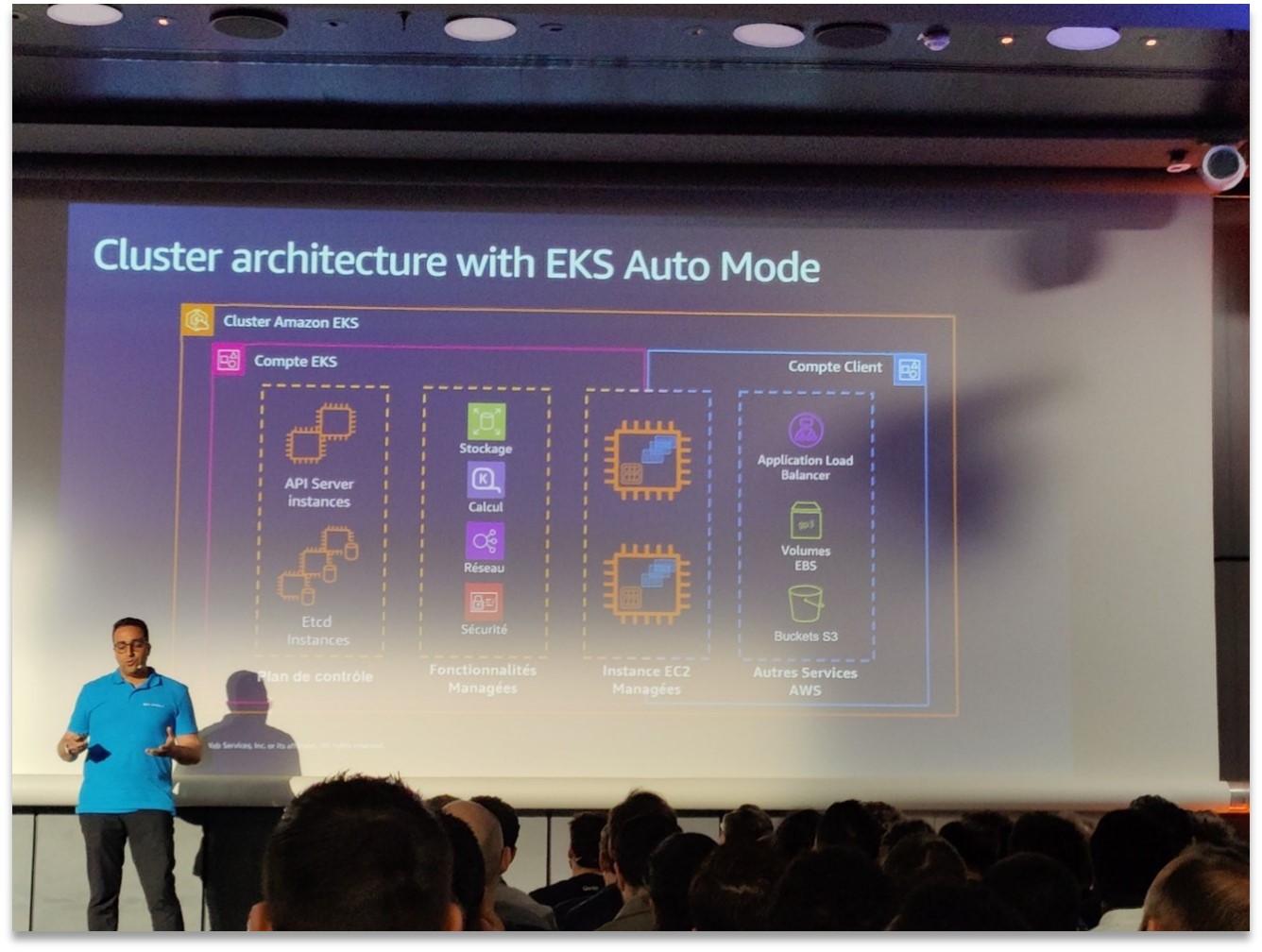
Architecture de cluster EKS Auto Mode avec gestion automatisée du scaling, du réseau et du stockage par AWS.
L’EKS Auto Mode (annoncé récemment par AWS) permet de créer des clusters Kubernetes managés encore plus autonomes. Concrètement, en activant ce mode, c’est AWS qui prend en charge automatiquement le provisioning des nœuds (via Karpenter), le scaling des workers en fonction des pods, mais aussi une partie de la configuration réseau et du stockage. Le schéma ci-dessus montre l’architecture simplifiée d’un cluster EKS Auto : le plan de contrôle reste géré par AWS comme d’habitude, mais désormais les instances de calcul (EC2) ainsi que des composants comme les load balancers, volumes EBS ou buckets S3 peuvent être provisionnés de façon dynamique et pilotés par la plateforme elle-même. Pour les équipes, cela signifie moins de gestion manuelle des infrastructures Kubernetes et plus de temps pour se concentrer sur les workloads applicatifs. Lors de la session sur ce thème, on a pu voir des démos de création de clusters en quelques commandes, sans avoir à se soucier du type d’instance ou des réglages de capacité – idéal pour des environnements de dev/test, des POC rapides, ou même pour de la prod dès lors que l’on a bien défini ses besoins de base.
Du point de vue Platform Engineering, EKS Auto Mode est une avancée majeure car elle démocratise l’accès à un K8s bien géré, même pour des équipes qui n’ont pas d’experts K8s à plein temps. Bien sûr, les puristes ou besoins spécifiques pourront toujours personnaliser (Auto Mode permet des ajustements réseaux, choix de types de nœuds, etc.). Mais pour beaucoup d’organisations, cette offre managé va accélérer le time-to-market en réduisant la charge Ops. On peut y voir l’aboutissement de tendances amorcées plus tôt : l’open source Karpenter (l’auto-scaler d’instances spot développé par AWS) a montré la voie pour optimiser les coûts et la flexibilité des clusters. D’ailleurs Anthropic avait témoigné l’an dernier d’une réduction de 40 % de sa facture AWS grâce à Karpenter. Aujourd’hui, AWS intègre ces mécanismes en natif dans EKS Auto : plus besoin d’installer/configurer Karpenter séparément, l’auto-provisioning est built-in. On gagne en simplicité ce qu’on perd (un peu) en contrôle fin.

L’équipe SRE de Qonto gère 15 clusters EKS (env. 20 000 pods) avec plus de 150 déploiements par jour, grâce à GitOps/ArgoCD et l’auto-scaling Karpenter. Leur session au Summit montrait comment les mises à jour de plateforme, qui prenaient autrefois plusieurs jours, sont passées à une heure seulement grâce à ces optimisations.
Par ailleurs, le GitOps s’est confirmé comme une pratique incontournable du platform engineering. Que ce soit pour déployer des applications ou gérer la configuration des clusters EKS, de nombreux speakers ont mentionné l’utilisation d’outils GitOps (Argo CD, FluxCD) afin d’assurer une traçabilité et une reproductibilité des changements. Couplé à des solutions comme EKS Auto Mode, le GitOps permet d’atteindre un haut niveau d’automatisation tout en gardant le contrôle via le code. On entrevoit ainsi des plateformes internes “self-service” où développeurs et data scientists peuvent déployer leurs applications (y compris des pipelines ML ou des modèles AI) en quelques clics, l’infra étant gérée as-code en arrière-plan.
Enfin, le mouvement Platform Engineering dans son ensemble se confirme. AWS a beaucoup communiqué sur les moyens d’industrialiser l’usage du cloud : des blueprints Terraform ou CDK pour déployer rapidement des plateformes complètes (intégrant CI/CD, observabilité, etc.), l’adoption grandissante de GitOps pour tout (plusieurs sessions montraient ArgoCD en action), et l’importance de l’automatisation end-to-end. Un message sous-jacent était clair : pour tirer pleinement parti de la GenAI et des nouvelles technos, il faut des fondations solides et automatisées. En tant que Tech Lead, cela me conforte dans l’idée qu’investir dans une plateforme interne robuste (Infrastructure as Code, pipelines, monitoring, sécurité intégrée) n’est pas du luxe, mais un prérequis pour innover vite et bien.

AWS Graviton4 : +30 % de performance par rapport à Graviton3, +40 % sur les bases de données, +45 % sur les applications Java.
Côté infrastructure & optimisation, AWS a également présenté ses dernières avancées matérielles. La nouvelle génération de processeurs maison Graviton4 a été dévoilée, promettant des gains significatifs : +30 % de performances par rapport à Graviton3 en général, et même +40 % sur les charges de bases de données et +45 % sur les applications Java. Ces améliorations matérielles se traduiront pour les équipes Ops par des coûts moindres (puisque plus de performances par dollar dépensé) et la possibilité de faire tourner des workloads intensifs (big data, entraînement de modèles ML, etc.) avec une efficacité accrue. Pour la communauté DevOps, c’est un rappel que l’optimisation passe aussi par le choix judicieux de l’infrastructure : tirer parti des dernières offres AWS (instances Graviton, GPU optimisés, stockage I/O-optimisé, etc.) fait partie intégrante de la démarche d’excellence opérationnelle.
De l’idéation à la production : bonnes pratiques pour l’IA générative
Clôturons ce retour d’expérience par un aspect transversal qui m’a marqué : comment passer de l’expérimentation à la production dans les projets d’IA générative ? Beaucoup d’intervenants ont insisté sur les bonnes pratiques pour réussir cette transition.
Le cycle de vie d’un projet GenAI a été décortiqué dès la keynote via le concept des “AI Foundations”. En amont, cela commence par la préparation des données (data readiness). Pas de modèle performant sans données de qualité : plusieurs speakers (dont Safran et Owkin) ont souligné l’importance de moderniser et centraliser les données d’entreprise avant de plonger dans le deep learning. Sur ce point, des services comme AWS Glue, Lake Formation ou l’intégration d’Apache Iceberg avec S3 (annoncée lors du Summit) viennent aider à créer des lacs de données gouvernés, versionnés, prêts à alimenter les modèles. J’ai noté par exemple qu’Owkin a monté des pipelines MLOps sur AWS pour agréger des données médicales multi-sources tout en garantissant l’anonymisation, preuve qu’on peut concilier richesse de la data et conformité.
Une fois le modèle choisi, la question du fine-tuning a été largement discutée. La tendance est à la parcimonie : on fine-tune seulement si nécessaire. Beaucoup de cas d’usage peuvent déjà être couverts en utilisant un prompt engineering soigné sur un modèle générique, ou via des techniques de embedding + RAG (Retrieval Augmented Generation) pour apporter la connaissance métier sans altérer le modèle. Le fine-tuning intervient pour apporter un vrai plus (ton spécifique, jargon métier, performance sur une tâche pointue) et doit se faire dans le respect des règles de sécurité (pas de fuite de données dans le set d’entraînement, usage de feature stores pour tracer ce qui a servi à entraîner, etc.). J’ai retenu également que AWS propose des outils pour faciliter ce fine-tuning en gardant un œil sur la dérive du modèle (model drift) et en permettant de distiller le modèle fine-tuné si besoin (pour en faire une version plus légère exploitable en production sur du matériel standard).
En synthèse, les meilleures pratiques de production pour l’IA générative mises en avant au Summit tiennent en quelques points : une donnée bien préparée et gouvernée, une sélection judicieuse des modèles (et de leur orchestration), une architecture intégrée au reste de l’écosystème applicatif, et une sécurité “by design” (garde-fous, monitoring, contrôle d’accès) tout au long du pipeline. Cela peut sembler beaucoup d’exigences, mais c’est à ce prix que l’IA générative délivrera sa valeur sur le terrain. En tant que tech lead, ces conseils résonnent fortement avec ma propre expérience : le diable se cache dans les détails (un modèle brillant en démo peut échouer en prod faute de données à jour ou d’ops adéquat), d’où l’importance d’une approche full-stack englobant modèle et infrastructure.
Last but not least ! n’oublions pas le volet formation et culture. Le Summit a montré que la technologie est prête (ou se prépare activement) pour la GenAI, mais la réussite de son adoption passe aussi par l’acculturation des équipes. Il est important de former les développeurs aux nouvelles pratiques (prompt engineering, utilisation des API d’IA, MLOps), de sensibiliser les équipes sécurité aux spécificités des LLM, et d’impliquer les métiers pour identifier les bons cas d’usage.
Un futur prometteur, des fondamentaux inchangés
Ce AWS Summit Paris 2025 aura su combler mes attentes de technophile. J’en ressors à la fois stimulé par les nouveautés et conforté dans mes convictions. Oui, l’IA générative est désormais assez mûre pour des usages concrets à grande échelle, et AWS fournit un écosystème robuste (puces dédiées, modèles variés, outils de déploiement) pour en tirer parti. Oui, l’approche multi-agents s’annonce comme la prochaine étape, ouvrant des perspectives inédites que nous allons explorer avec passion, mais en gardant à l’esprit les défis d’orchestration et de sécurité que cela pose. Et justement, sur la sécurité, je salue la lucidité de rappeler que sans confiance et gouvernance, aucune innovation ne s’inscrit dans la durée – à nous de mettre en œuvre ces garde-fous dans nos projets dès maintenant.
En filigrane, ce Summit rappelle que les fondamentaux DevOps/DevSecOps restent plus pertinents que jamais. Qu’il s’agisse de déployer un chatbot piloté par un LLM ou une application cloud plus classique, les recettes qui marchent sont identiques : une plateforme automatisée, scalable et observable, des pipelines de CI/CD fluides, une culture de l’amélioration continue et du share knowledge. Les outils évoluent (Kubernetes devient autopiloté, l’IA s’invite partout) mais notre mission d’ingénieurs reste de garder la maîtrise – maîtrise technique, opérationnelle, et éthique – de ces puissantes technologies.
Pour Squad et notre communauté tech, l’aventure continue donc avec un cap clair. Ce retour d’expérience de l’AWS Summit 2025 n’est pas une fin en soi, mais un point de passage inspirant. À nous de transformer l’essai en appliquant ces insights dans nos prochains projets DevSecOps et MLSecOps, en partageant à notre tour nos trouvailles, et en gardant toujours cet équilibre entre enthousiasme pour l’innovation et exigence de fiabilité. Comme j’aime à le dire : “Innover, c’est bien… innover sûr et robuste, c’est mieux” !


