
GenAI : illusion d’intelligence et sobriété selon Luc Julia

Ambiance de la grande salle lors de la keynote d’ouverture. La scène principale de Devoxx France 2025 a accueilli Luc Julia pour un discours sans filtre sur l’IA.
La conférence d’ouverture a donné le ton : Luc Julia – co-créateur de Siri et directeur scientifique de Renault – a livré un discours captivant et critique sur l’intelligence artificielle et plus particulièrement l’IA générative. Le titre provocateur de son keynote, “L’Intelligence Artificielle n’existe pas”, annonçait déjà la couleur. Selon lui, le terme même d’IA est source de confusion : ces systèmes, y compris les modèles de langage type GPT, ne “pensent” pas et n’ont rien d’intelligent au sens humain du terme. Il a martelé que derrière ChatGPT, il n’y a pas de magie, juste des statistiques sur d’énormes volumes de données – ce qui explique d’ailleurs les réponses parfois farfelues ou les “hallucinations” produites par ces modèles.
Luc Julia a ainsi démonté un certain nombre de mythes en rappelant que chaque IA reste spécialisée dans un domaine précis et que la créativité et le discernement restent l’apanage de l’homme. J’ai particulièrement retenu son analogie de l’IA comme une simple “boîte à outils” : à nous de l’apprivoiser, de l’entraîner avec des données fiables, et de l’utiliser à bon escient pour des tâches bien définies. Sur le volet éthique, il a souligné que l’éthique de l’IA est avant tout celle de ses créateurs – en d’autres termes, c’est à nous de fixer les règles d’usage, exactement comme un marteau peut servir à construire ou à blesser selon l’intention de l’utilisateur.
Enfin, un message fort portait sur la sobriété numérique : “L’IA générative est une aberration écologique”, a-t-il lancé en substance, chiffres à l’appui. Si l’on effectuait autant de requêtes à un chatbot qu’on en fait à Google, la consommation d’énergie serait exorbitante et intenable. En tant que professionnels, cela nous rappelle la nécessité de garder la tête froide face au battage médiatique : avant de déployer le dernier modèle à la mode, assurons-nous de sa pertinence métier et de son efficience. Cette remise en perspective par Luc Julia m’a semblé salutaire pour aborder la suite de la conférence avec pragmatisme.
Réglementation et sécurité : CRA, SBOM et DevSecOps en action
Le milieu de matinée a été marqué par un excellent talk axé sur la conformité et la sécurité, autour du nouveau Cyber Resilience Act (CRA) européen. Les intervenants (une équipe de Thales) ont détaillé les exigences de cette réglementation à venir et son impact sur nos pratiques DevSecOps. Pour faire simple, le CRA imposera aux produits numériques une série d’obligations de sécurité by design et de suivi des vulnérabilités tout au long du cycle de vie.

Slide présenté par Thales listant les exigences clés du Cyber Resilience Act : principes de Security by Design et gestion proactive des vulnérabilités.
Cette slide résume bien l’esprit du CRA : intégrer la sécurité dès la conception (analyse de risques, configuration sécurisée par défaut, contrôle des accès, protection des données, réduction de la surface d’attaque, traçabilité des actions sensibles…) et mettre en place une gestion des vulnérabilités exemplaire (inventaire des dépendances et des failles, tests de sécurité réguliers, correction des vulnérabilités sans délai, mise à jour continue et mécanismes de remontée des vulnérabilités). Autrement dit, fini le temps où l’on pouvait traiter la sécurité plus tard ou “en option” : il faudra pouvoir démontrer que notre application respecte ces bonnes pratiques de façon systématique.
Un point concret abordé a été le rôle du SBOM (Software Bill of Materials) : maintenir la liste à jour de toutes les librairies et composants open source utilisés, avec leurs versions et éventuelles CVE, devient indispensable pour se conformer aux exigences de transparence du CRA. En pratique, cela signifie intégrer des outils d’analyse de dépendances et de veille de vulnérabilités dans nos pipelines CI/CD. Les speakers ont d’ailleurs insisté sur l’automatisation : face à l’ampleur des contrôles requis, seul un outillage DevSecOps permet de “scaler” la conformité.

Pipeline d’industrialisation de la sécurité présenté dans le cadre du CRA : dès la détection d’une vulnérabilité, une correction est intégrée et déployée via l’intégration continue, avec batteries de tests (unitaires, non-régression, performance) avant mise en production.
Ce schéma illustre l’approche DevSecOps recommandée pour répondre au CRA : il faut raccourcir au maximum le temps entre la découverte d’une faille et son déploiement en production. Idéalement, dès qu’une vulnérabilité est signalée (par exemple dans une librairie tierce), l’équipe produit la prend en charge immédiatement, la corrige, puis déclenche le pipeline CI/CD qui va tester la mise à jour (tests unitaires, d’intégration, de non-régression, de performance…) afin de livrer une version corrigée sans délai. On voit qu’on est loin du cycle de patch management traditionnel en plusieurs semaines : le temps réel devient la norme. En tant que responsable DevSecOps, je vois dans ce défi une opportunité d’accélérer encore l’automatisation (scans de sécurité, déploiements, génération de rapports de conformité) afin de transformer une contrainte réglementaire en avantage qualité. Certes, se plier en quatre pour la conformité peut sembler lourd, mais in fine, un produit plus sûr, mis à jour en continu, c’est aussi moins d’incidents et de crises à gérer.
AppSec et pédagogie par le storytelling
La sécurité applicative a aussi eu son heure de gloire, de manière très originale, via une présentation qui sortait des sentiers battus. Intitulé “Il était une faille : 5 histoires d’AppSec et ce qu’on peut en apprendre”, le talk de Paul Molin (CISO chez Theodo) a captivé l’assistance en utilisant le storytelling pour faire passer des messages de sécurité. Plutôt que de lister des bonnes pratiques de façon magistrale, il a raconté des histoires vraies de failles et d’attaques, un peu comme des contes modernes, pour en tirer des leçons concrètes. L’approche est rafraîchissante et diablement efficace pour marquer les esprits des développeurs : on se souvient bien mieux d’une anecdote frappante que d’une énième checklist OWASP apprise par cœur.
Un des récits marquants évoquait une fuite de donnéesmassive touchant plusieurs enseignes françaises connues. En septembre dernier, un même attaquant a compromis les bases clients de plusieurs marques de retail, exposant des millions d’enregistrements (noms, emails, téléphones…). Boulanger, Cultura, Grosbill, Truffaut… aucune n’y a échappé, et chacune a dû envoyer en catastrophe des notifications à ses clients pour avouer l’incident.
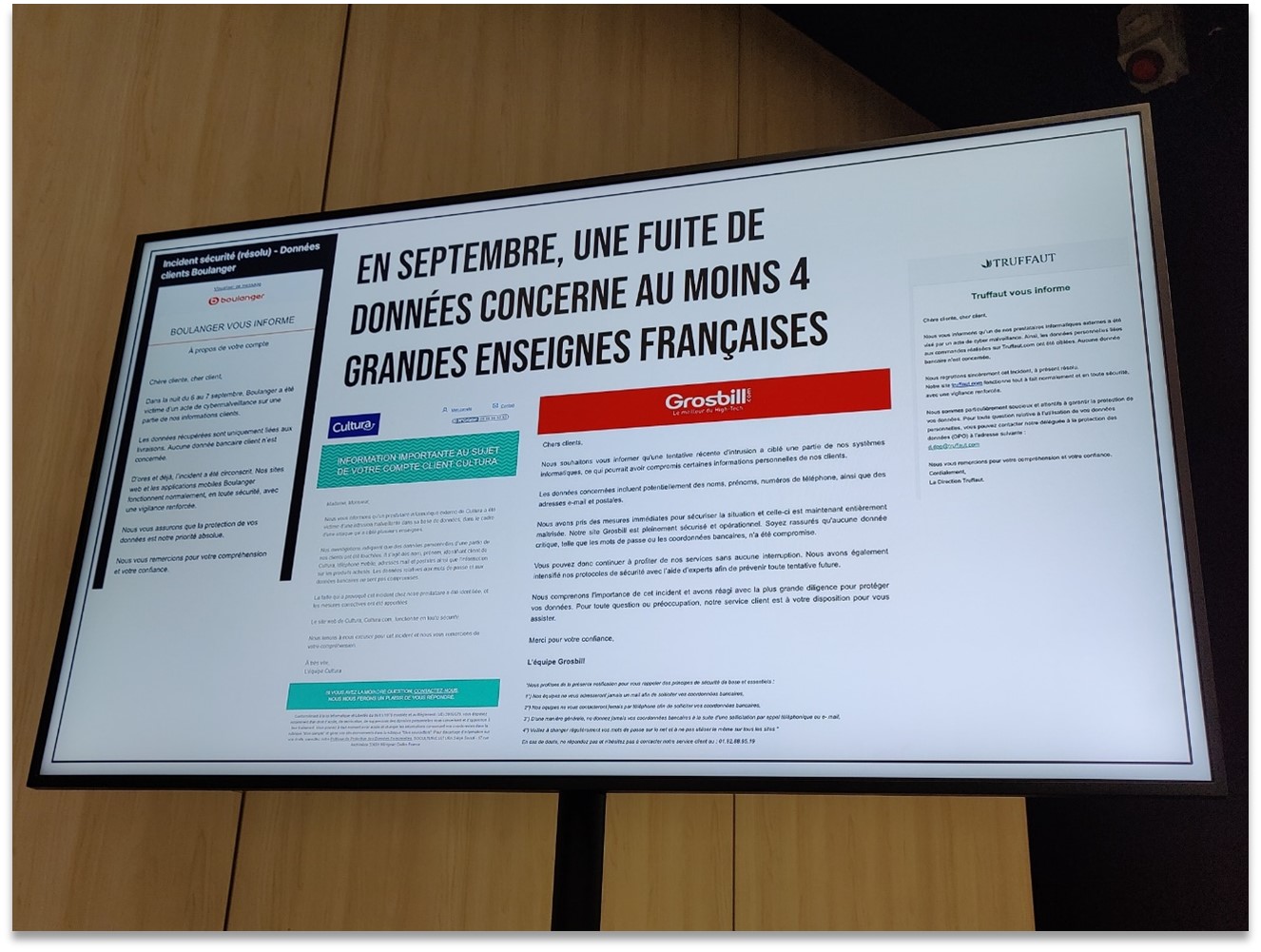
Exemple de failles présentées : en septembre 2024, les données clients d’au moins quatre grandes enseignes françaises (Boulanger, Cultura, Grosbill, Truffaut) ont fuité suite à l’attaque d’un même hacker, exposant les faiblesses de sécurité de ces entreprises.
Ce cas concret a permis d’illustrer plusieurs points : d’une part, même les grands noms ne sont pas à l’abri et un attaquant motivé peut causer des dégâts en série si des vulnérabilités communes existent (on pense à des fournisseurs partagés ou des défauts similaires exploités sur chaque site). D’autre part, la manière dont chaque enseigne a géré la communication de crise a été disséquée, soulignant l’importance de la transparence envers les utilisateurs en cas d’incident. En vivant cette histoire du point de vue du “méchant” et des victimes, l’auditoire prend conscience des impacts réels d’une faille de sécurité, bien au-delà de la théorie.
Les autres histoires couvraient des domaines variés (de la petite faille front-end insolite à l’attaque sophistiquée sur une chaîne d’approvisionnement logicielle), avec à chaque fois une morale ou un enseignement pour les développeurs et les architectes. J’ai adoré la démarche qui consiste à rendre la sécurité fun et narrative. C’est une piste pédagogique à retenir : pourquoi ne pas incorporer ce genre d’histoires dans nos formations internes ou nos sensibilisations sécurité ? Le storytelling, s’il est bien utilisé, peut transformer la sécurité en quelque chose de concret et mémorable plutôt que perçu comme une contrainte abstraite.
Par ailleurs, durant la pause déjeuner, j’ai assisté à un mini-talk sur un sujet de sécu plus atypique : le Port Knocking. Derrière ce nom intriguant se cache une technique ancienne, quasiment ésotérique, pour renforcer l’accès à un serveur. Le principe : le serveur n’ouvre le port (ex : SSH) qu’après une séquence particulière de “coups” (connexions sur une série de ports dans un ordre convenu). Paul Jeannot nous a fait un tour d’horizon de cette méthode intitulé “Port Knocking : le “Sésame, ouvre-toi” du SSH”. C’était l’occasion de revoir ce mécanisme de sécurité par obscurité bien connu des barbus, et de discuter de sa pertinence actuelle.

Slide de conclusion du talk sur le Port Knocking – En résumé : une solution intéressante surtout pour des petits serveurs isolés ou des homelabs, avec des clients disponibles sur toutes plateformes. C’est une friction supplémentaire qui peut éviter des attaques opportunistes, mais difficile à déployer à grande échelle en entreprise. En cas d’utilisation, prévoir un mécanisme d’OTP pour éviter les rejeux de séquence.
La conclusion est sans appel : le port knocking peut apporter une petite couche de sécurité additionnelle (une “friction salvatrice” qui arrête les bots les plus basiques), mais il devient vite agaçant et complexe sur une infrastructure importante. Mieux vaut réserver cette astuce à des cas très spécifiques (serveurs persos, labos) et ne pas en abuser en production. J’ai apprécié que le speaker mentionne l’ajout d’un code à usage unique (TOTP) pour renforcer le procédé si on décide vraiment de l’implémenter – preuve qu’on peut moderniser un peu cette vieille recette. En somme, un sujet léger mais instructif, qui nous rappelle qu’en sécurité il n’y a pas de solution miracle : chaque mesure a ses limites et son contexte d’application.
Kubernetes, IaC, snapshots… et observabilité distribuée
Impossible de passer à Devoxx sans parler Infrastructure et Cloud Native. L’après-midi a offert plusieurs sessions autour de Kubernetes, de l’Infrastructure as Code et de l’observabilité, que je regroupe ici car elles dessinent ensemble les contours de l’écosystème moderne DevOps/Cloud.
D’abord, un état des lieux de Kubernetes en 2025 nous a été proposé (notamment par Alain Regnier lors d’une conférence en salle principale). Ce que j’en retiens, c’est que Kubernetes s’est imposé comme un standard de fait – au point qu’on en oublie presque sa présence tant il est devenu banal d’avoir des clusters pour tout et n’importe quoi. La question n’est plus “Faut-il adopter K8s ?” mais “Comment le rendre invisible pour les développeurs et maîtrisable pour les Ops ?”. On a parlé de la montée en puissance des offres managées (pour ne plus se soucier du control plane), de l’importance croissante de l’optimisation des coûts (arrêter de sur-provisionner des clusters ou de lancer 1000 pods quand 100 suffisent), et de la tendance à aller vers des architectures hybrides multi-cloud ou edge qui complexifient la donne. En clair, Kubernetes n’est plus la nouveauté hype, c’est un outil mature dont on cherche maintenant à lisser les aspérités (simplifier son usage, améliorer sa sécurité intrinsèque, etc.).
Un sujet précis m’a particulièrement intéressé : la gestion des données et sauvegardes dans Kubernetes. Lors d’un talk technique, j’ai redécouvert (démonstration à l’appui) les VolumeSnapshots Kubernetes. Pour ceux qui ne connaissent pas, il s’agit d’une fonctionnalité qui permet de capturer un instantané d’un volume persistant (PersistentVolumeClaim) – un peu comme une sauvegarde à chaud de votre disque attaché – et ce directement via l’API Kubernetes.

Extrait de démo Kubernetes : création d’un snapshot de volume via la CLI . On voit la configuration du projet, de la zone et l’utilisation d’un CustomResourceDefinition (CRD) “VolumeSnapshot” pour déclencher la copie des données. Ce snapshot pourra ensuite être restauré si besoin.
La démo, réalisée sur Google Cloud (GKE), montrait les commandes pour configurer le projet et la région, puis créer une ressource VolumeSnapshot Kubernetes pointant vers un disque persistant. Cela a mis en évidence que tout n’est pas natif dans Kubernetes : le support des snapshots nécessite que le fournisseur de stockage sous-jacent l’implémente (ici via les drivers CSI de GCP). En arrière-plan, cette fonctionnalité introduit de nouveaux objets (CRD) dans le cluster. En tant qu’infra/code enthusiast, voir ce genre de mécanisme en action est fascinant : on traite l’infrastructure (ici la sauvegarde de volumes) “as Code”, déclenchée par de simples objets YAML dans le cluster, ce qui ouvre la voie à l’automatisation de sauvegardes/restaurations, à la portabilité des données entre environnements, etc. C’est le genre de détail qui rappelle que même une fois la plateforme Kubernetes en place, il reste des défis techniques pointus pour gérer tout l’écosystème (stockage, réseau, etc.) via l’IaC.
Parlons justement d’Infrastructure as Code (IaC) : elle était en présente dans quasiment toutes les sessions infrastructure. Que ce soit pour décrire des déploiements Kubernetes, orchestrer du cloud avec Terraform, ou même coder des politiques de sécurité, on voit que l’approche déclarative est partout. Un exemple marquant de l’après-midi fut l’importance de la GitOps et du déploiement ultra simplifié. Un outil comme Kamal (présenté en Tool-in-Action) promet de déployer une application en “10 lignes de configuration” – signe que la communauté cherche à abstraire toujours plus la complexité Kubernetes pour revenir à l’essentiel (déployer du code). De mon côté, je constate dans nos projets que l’IaC est devenu indispensable pour la reproductibilité et la traçabilité : plus question de créer une ressource à la main via console web sans avoir son équivalent dans Git. Ce mouvement vers l’IaC total continue donc de s’accélérer, avec des solutions qui rivalisent d’ingéniosité pour rendre ça accessible.
Autre grand thème technique de la journée : l’observabilité distribuée. Un duo de speakers (Alexandre Moray et Florian Meuleman) a présenté les outils-clés pour survivre quand la prod plantera – tout un programme ! L’idée maîtresse : préparer les développeurs (pas que les Ops) à faire face aux incidents dans des systèmes complexes. On a souvent des microservices partout, des requêtes qui transitent par N files, M bases de données… Quand ça tombe en panne, il faut être capable de tracer le fil d’exécution et de comprendre où ça coince. Le talk a mis en avant l’utilisation d’OpenTelemetry pour instrumenter son code dès le départ, de façon standard, afin de collecter des métriques et des traces exploitables plus tard. Ils ont également fait la promo de solutions open source comme SigNoz, une plateforme d’observabilité qui permet d’agréger et visualiser logs/traces/metrics (une alternative maison aux Datadog & co). J’ai retenu qu’en couplant OpenTelemetry (pour la collecte unifiée) et un outil comme SigNoz (pour l’analyse), on obtient un écosystème 100% open source, qu’on peut héberger soi-même, pour monitorer ses apps. Pour nous, praticiens DevSecOps, c’est une bonne nouvelle : on peut outiller nos équipes dev avec des solutions d’observabilité accessibles, sans forcément exploser le budget en APM propriétaire, et surtout en les intégrant nativement dans le cycle de dev. En bref, le message était “la panne arrivera tôt ou tard, soyez prêts : mettez des capteurs partout, des dashboards utiles, et entraînez-vous à lire ces signaux”. Une piqûre de rappel importante pour ne pas considérer l’observabilité comme un luxe, mais comme un composant essentiel de l’infrastructure dès la conception.
Open source et opérateurs intelligents : l’exemple de Burrito
En fin de journée, un autre sujet m’a enthousiasmé : la puissance de l’open source pour améliorer nos pipelines DevSecOps, illustrée par un outil au nom surprenant – Burrito. Sous ce nom facétieux se cache un Kubernetes Operator open source développé par Theodo, visant à simplifier l’automatisation d’infrastructure Terraform. Les speakers (Lucas Marques et Luca Corrieri) l’ont présenté comme un “TACoS” – pour Terraform Automation & Collaboration Software. En clair, Burrito se positionne comme une alternative libre à des solutions comme Terraform Cloud/Enterprise : il permet de lancer des plans et applies Terraform de manière automatisée, déclenchée par des événements (merge de pull request, push sur une branche, etc.), avec gestion des états, des accès et même détection de drift (dérive entre l’infra codée et l’infra réelle).
J’ai été impressionné de voir comment Burrito s’intègre nativement dans Kubernetes – puisqu’il fonctionne comme un opérateur dans le cluster. Concrètement, il surveille des Custom Resources représentant vos stacks Terraform, et se charge en arrière-plan de gérer les containers Terraform qui vont appliquer les changements. On reste donc dans l’esprit GitOps : dès que je modifie la description de mon infra dans Git, l’opérateur va orchestrer Terraform pour réconcilier l’état réel. Le tout sans sortir de mon cluster Kubernetes, et avec la possibilité de tout tracer dans les logs du cluster. C’est assez élégant et cela évite de dépendre d’un service SaaS externe.
Au-delà de Burrito lui-même, ce talk met en lumière une tendance de fond : l’intelligence dans les opérateurs Kubernetes. On a commencé à utiliser des opérateurs pour des bases de données, des brokers, etc. – maintenant on les étend à des cas d’usage DevOps. Ils deviennent de vrais chefs d’orchestre capables de piloter d’autres outils (ici Terraform) tout en bénéficiant du contrôle de version, des permissions K8s et de la résilience du cluster. Pour nous qui faisons du DevSecOps, c’est une aubaine : on peut combiner le monde des plateformes (K8s) avec celui de l’infrastructure-as-code de manière fluide. Et le fait que ce soit open source signifie qu’on peut l’adapter, l’auditer, contribuer… Bref, un bel exemple de projet communautaire utile, né d’un besoin réel (comment améliorer nos pipelines IaC) et mis à disposition de tous.
Je repars de la session Burrito avec plein d’idées en tête : pourquoi ne pas tester cette approche sur nos propres environnements de staging ? S’il tient ses promesses, cela pourrait simplifier la vie de nos équipes d’infra en leur offrant un Terraform-as-a-Service interne, maîtrisé de bout en bout.
DEVOXX 2025 : Entre lucidité et pragmatisme technique
Cette première journée de Devoxx France 2025 fut intense, couvrant un spectre très large allant de la vision stratégique (IA, réglementation) jusqu’aux outils concrets du quotidien (Kubernetes, Terraform, sécurité applicative). Le fil rouge que j’y vois en tant que praticien DevSecOps, c’est l’importance de la transversalité : réussir à connecter les points entre ces mondes. Par exemple, intégrer l’IA de manière raisonnée dans nos produits tout en respectant les contraintes de sécurité et d’éthique. Ou encore, se conformer aux nouvelles lois (CRA) sans casser l’agilité, grâce à l’automatisation. C’est aussi sensibiliser les devs à la sécu via des méthodes nouvelles comme le storytelling, tout en leur fournissant des plateformes technologiques robustes (K8s, pipelines IaC outillés) et des outils open source innovants. En une seule journée, j’ai pu faire le plein de retours d’expérience et de bonnes pratiques que j’ai hâte de partager avec mes collègues et équipes. Devoxx France prouve une fois de plus que l’on repart avec l’enthousiasme de tester plein de nouvelles choses. Vivement les prochaines sessions et discussions à venir !


