
Por Amir BENYEKKOU – Ingeniero de Sistemas, Infraestructura Virtual en Squad
Este segundo artículo aborda los problemas relacionados con un entorno VMware vSphere en el que la sobreasignación de recursos puede provocar una disminución del rendimiento de las cargas de trabajo virtualizadas. Solo se tratará la resolución de problemas relacionados con los hipervisores ESXi. Los problemas de rendimiento relacionados con la configuración de las funciones de clúster y alta disponibilidad (HA) de VMware vSphere no se tratarán aquí.
Para cada componente (CPU, memoria, red y almacenamiento) existen contadores específicos que se pueden supervisar y que pueden revelar una falta de optimización de la infraestructura virtualizada. Estos contadores se pueden supervisar mediante la interfaz gráfica integrada en la consola web, para una gestión de la capacidad, o bien a través de la línea de comandos, para un enfoque orientado a la resolución de problemas.
Para obtener el máximo rendimiento de un entorno, hay que seguir dos prácticas:
- Comprender las necesidades de las aplicaciones y las características de las cargas de trabajo
- Optimizar la configuración de las máquinas virtuales para ofrecer el mejor entorno a las cargas de trabajo.
Guía de resolución de problemas
El siguiente esquema muestra el proceso básico de resolución de problemas de un host ESXi. La lista de comprobación abarca la mayoría de los problemas de rendimiento en un ESXi:
- Problemas directos: problemas que tienen un efecto directo y que deben solucionarse.
- Problemas habituales: situaciones que suelen afectar directamente al rendimiento
- Posibles problemas: situaciones que pueden ser indicativas de un problema, pero que también pueden reflejar condiciones normales de funcionamiento.
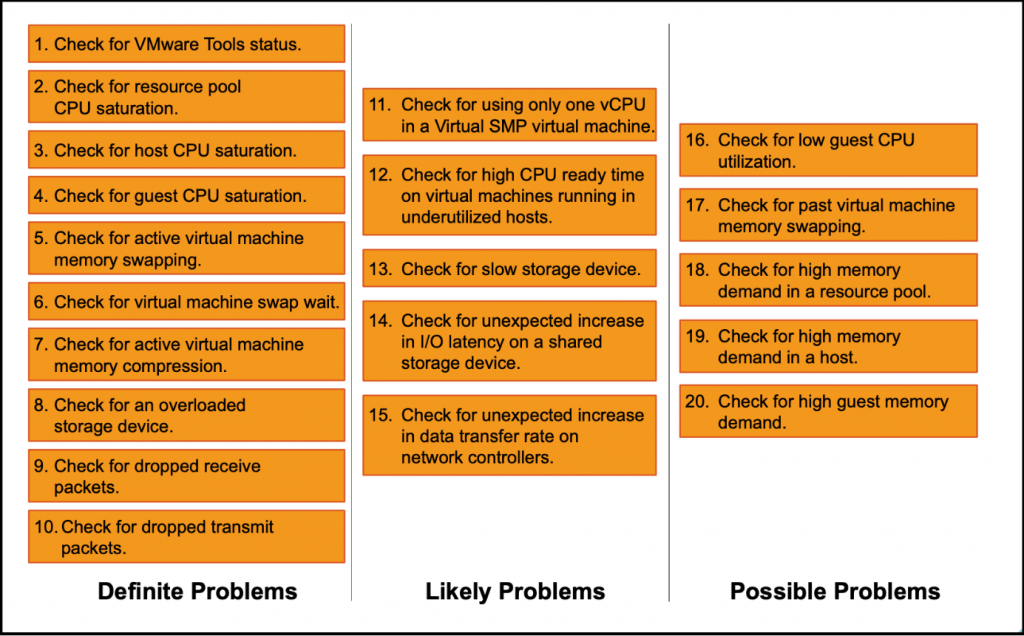
Todos estos problemas pueden detectarse mediante el cliente de supervisión de VMware vSphere o con la herramienta de línea de comandos esxtop en vCenter o en los hosts ESXi.
Solución de problemas de rendimiento de la red
La herramienta esxtop, junto con otras herramientas, permite visualizar el estado de la red en un momento dado, tanto en los vSwitch del host ESXi como en las tarjetas de red virtuales de las máquinas virtuales.

Los indicadores que se muestran se pueden configurar. Los dos indicadores más significativos son los paquetes descartados en transmisión/recepción (%DRPTX y %DRPRX)
Si la tasa de paquetes ignorados en la recepción es > 0:
- La causa puede ser un uso intensivo de la CPU dentro de la máquina virtual y, en ese caso, es necesario aumentar los recursos de CPU asignados a la máquina virtual o mejorar la eficiencia con la que esta utiliza dichos recursos.
- O bien, una configuración incorrecta de los controladores de red de la máquina virtual, por lo que es necesario mejorar la compatibilidad de la pila de red o distribuir la carga de red
Si la tasa de paquetes ignorados en la transmisión es > 0:
- El tráfico de las máquinas virtuales conectadas al mismo vSwitch supera la capacidad física de las tarjetas de enlace ascendente o de la infraestructura de red física subyacente. En este caso, es necesario añadir enlaces ascendentes al vSwitch, equilibrar la carga de red de las máquinas virtuales trasladándolas a otros vSwitch, mejorar la capacidad de la red física o reducir el tráfico de red.
También será necesario cotejar la información recopilada con la de la red física subyacente.
Si la velocidad de transferencia de datos aumenta muy rápidamente (MBTX/s o MBRX/s):
Los recursos de red están saturados debido a que varias funciones comparten un mismo enlace físico (por ejemplo, vMotion o Fault Tolerance). En este caso, se deben configurar cuotas, reservas y límites con Network IO Control para distribuir el tráfico entre los distintos tipos de flujos de red.
Solución de problemas de rendimiento del almacenamiento
Con esxtop habrá que tener en cuenta varios indicadores y será necesario compararlos en tres niveles: adaptador de almacenamiento físico (tarjeta HBA), dispositivo de almacenamiento físico (LUN) y disco virtual de la máquina virtual.
Los indicadores clave que se analizarán serán:
- La velocidad de lectura de los discos
- La latencia del núcleo y de los periféricos
- Número de comandos de disco fallidos, activos y en cola.


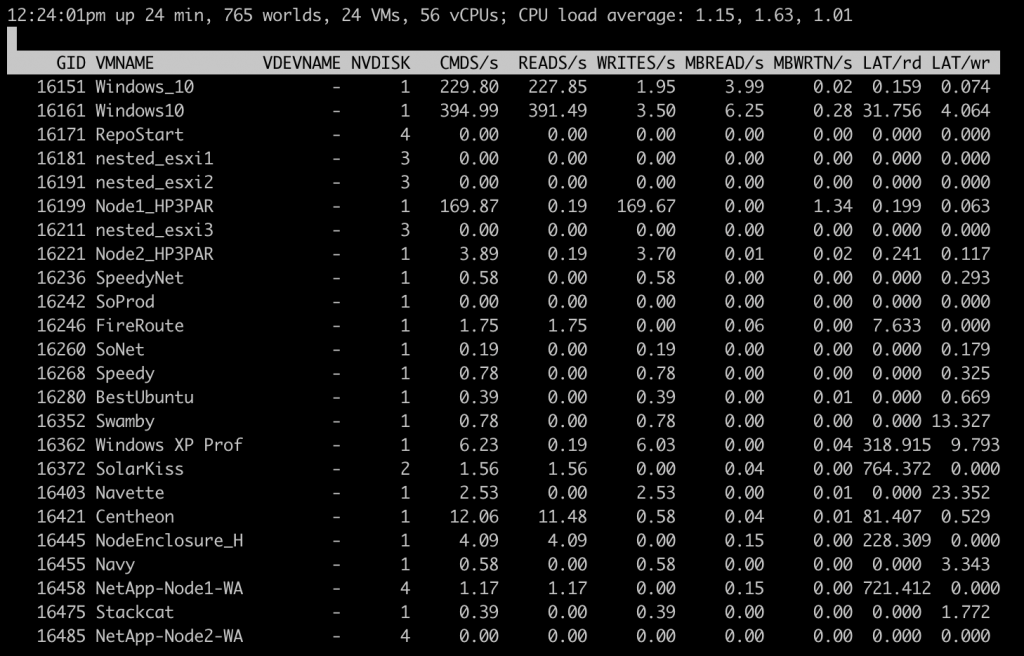
La suma de las lecturas por segundo (Reads/s) y las escrituras por segundo (Writes/s) es igual a las IOPS y permite comprobar si las IOPS no están al límite del almacenamiento subyacente.
En la vista de mapas de HBA:
Los indicadores DAVG/cmd y KAVG/cmd representan, respectivamente, la latencia media en milisegundos del dispositivo y del VMKernel.
El primer indicador corresponde al tiempo medio que tarda un dispositivo físico en completar un comando SCSI; esta métrica define el tiempo que tarda el dispositivo físico desde la tarjeta HBA hasta el sistema de almacenamiento subyacente.
El segundo corresponde al tiempo medio que tarda el VMKernel en procesar un comando SCSI; esta métrica mide el tiempo que transcurre entre el sistema operativo de la máquina virtual y su dispositivo virtual.
Si el primer indicador es > 20, el LUN es lento o está sobrecargado; si está entre 10 y 20, puede indicar un posible problema de rendimiento
Si el segundo indicador es > 2 ms, las máquinas virtuales intentan enviar más tráfico del que puede soportar el almacenamiento subyacente
La latencia total de una máquina virtual es la suma de la latencia del dispositivo (DAVG) y del VMkernel (KAVG). Si el indicador es superior a 10, puede haber un problema, y si es superior a 20, existe un problema de rendimiento.
En la vista de los LUN:
El número de comandos activos y en cola (ACTV y QUED) en los LUN permite detectar una posible congestión en los LUN. Si el número de comandos activos alcanza la profundidad máxima de la cola (DQLEN), los comandos se pondrán en cola, lo que provocará un aumento de la latencia.
El número de comandos fallidos (ABRT/s) en los LUN permite detectar si alguno de ellos está sobrecargado. En tal caso, habrá que comprobar si la configuración del nivel RAID, la caché o el número de discos por LUN se ajusta a los requisitos de las cargas de trabajo.
vSphere Storage IO Control permite controlar con mayor precisión las asignaciones por máquina virtual para reducir los conflictos en los recursos de almacenamiento.
Por último, la vista de máquinas virtuales permite obtener una visión más detallada de las máquinas virtuales y poder rastrear un problema de rendimiento de principio a fin.
Solución de problemas relacionados con el rendimiento del procesador
Los indicadores relacionados con el rendimiento del procesador son similares a los que se pueden encontrar en los sistemas Linux tradicionales, con algunas particularidades relacionadas con la virtualización y las máquinas virtuales
Los indicadores clave son:
- CPU utilizada en el host ESXi
- CPU utilizada por la máquina virtual
- CPU Ready por VM
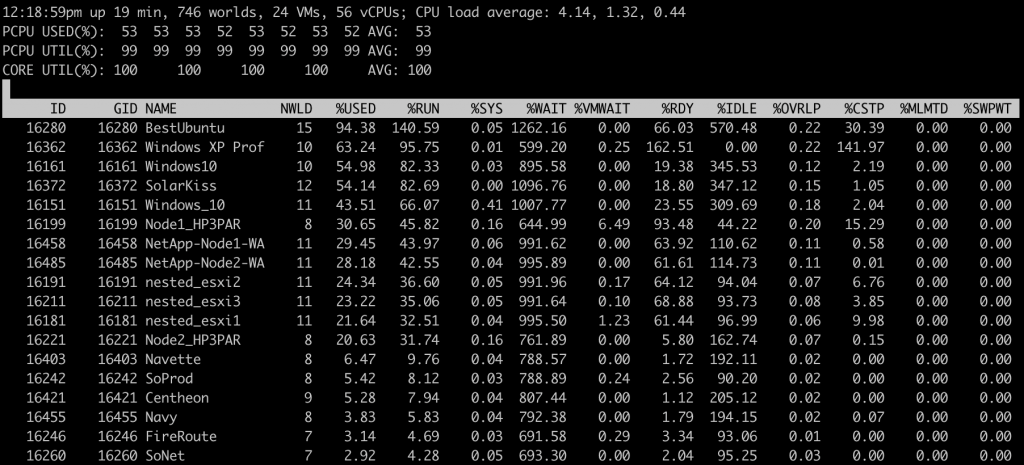
Los indicadores de esxtop más importantes son:
- % de CPU utilizada = Porcentaje de uso por CPU física
- %USED: Porcentaje de uso de la CPU por máquina virtual
- %SYS: Porcentaje del tiempo dedicado por el VMKernel a la gestión de interrupciones
- %RDY: Porcentaje de tiempo durante el cual una máquina virtual estaba lista para ejecutar instrucciones, pero no se le asignó ningún recurso de CPU física
- %WAIT: Porcentaje de tiempo que una máquina virtual pasa en estado ocupado o bloqueado
Unos valores elevados de uso de la CPU no indican necesariamente un problema de rendimiento, ya que ese es uno de los objetivos de los entornos virtualizados. Sin embargo, si se combinan con valores elevados de la cola de espera de red, pueden indicar un posible problema.
El indicador «ReadyTime» indica si hay más recursos de CPU que esperan ser programados en las CPU físicas del host. El programador de CPU del host pone en espera estas solicitudes porque las CPU físicas ya están sobrecargadas.
Si este indicador es superior al 10 %, conviene analizar la carga de trabajo de la máquina virtual:
- Seguir las buenas prácticas de configuración de aplicaciones en la máquina virtual
- Elegir el número adecuado de CPU para la máquina virtual
- Utilizar páginas de memoria de gran capacidad
- Ajustar los límites, las reservas y la memoria de la máquina virtual
- Aumenta la asignación de CPU en la máquina virtual si el sistema operativo invitado y sus aplicaciones consumen todos los recursos de CPU.
Pero también hay que comprobar si no hay una sobreasignación de vCPU en relación con las CPU físicas del host.
Solución de problemas de rendimiento: memoria
Las técnicas descritas en el primer artículo pueden ponerse de manifiesto a través de los distintos indicadores de esxtop.
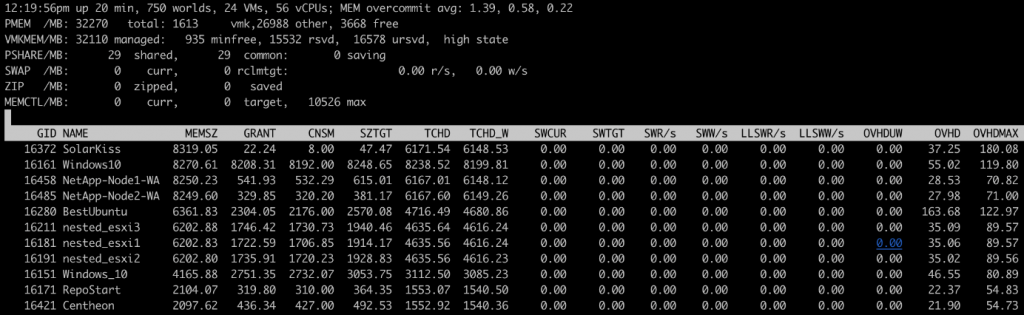
Hay que tener en cuenta varios indicadores clave:
- PMEM: Memoria física de ESXi; la suma de «vmk», «other» y «free» da como resultado la memoria física total
- VMKMEM: Memoria total gestionada por el VMKernel, es decir, la suma de la memoria reservada, no reservada y del vmkernel en la línea PMEM. También indica el estado (en este caso, «high state»). Cuanto más bajo es el estado, más técnicas de optimización de memoria se han aplicado.
- PSHARE: Estadísticas de memoria tras la aplicación de Transparent Sharing
- SWAP: Memoria total paginada por las máquinas virtuales con los valores SWR/s y SWW/s (velocidad de lectura/escritura en MB por cada máquina virtual)
- ZIP: Tamaño de la memoria comprimida por el host ESXi
- SWCUR: La cantidad de espacio de intercambio utilizada por la máquina virtual.
- SWTGT: La cantidad de espacio de intercambio que el host ESX prevé que utilizará la máquina virtual.
- MEMCTL: Estadísticas de Ballooning (solicitud de memoria a otros VMS en caso de conflicto)
- ¿MEMCTL? : Indica si las vmtools están instaladas en cada máquina virtual o no, para poder realizar el ballooning
- MCTLSZ: Memoria solicitada por el ballooning en cada máquina virtual
Los estados que se muestran en la consola (high state, clear, soft, hard, low) permitirán orientar el diagnóstico y comprender que, ante cada deterioro del estado general, se irán aplicando sucesivamente las técnicas para ahorrar memoria. Estos estados se alcanzan bien por una sobreasignación de memoria, bien por un número excesivo de máquinas virtuales en el host.
En ese caso, se pueden migrar las máquinas virtuales y, para garantizar una solución a largo plazo, se puede realizar un análisis del consumo de memoria de cada máquina virtual con el fin de redefinir la asignación o los límites y reservas de las mismas.
Artículo para volver a leer:
VMWare Vsphere: Optimización del rendimiento
