
La edición de 2024del All Days DevOps (ADDO)de Sonatype reunió a expertos de todo el mundo para debatir cuestiones fundamentales relacionadas con la seguridad del software, la infraestructura y el desarrollo nativo en la nube.
Más allá de las presentaciones individuales, surgieron temas transversales que pusieron de manifiesto tendencias y retos comunes a todos los niveles de la ingeniería y la innovación en software. Este RETEX recopila estos temas para ofrecer una visión general coherente de los retos y las soluciones presentados durante este evento.
Seguridad de las cadenas de suministro de código abierto: una amenaza silenciosa

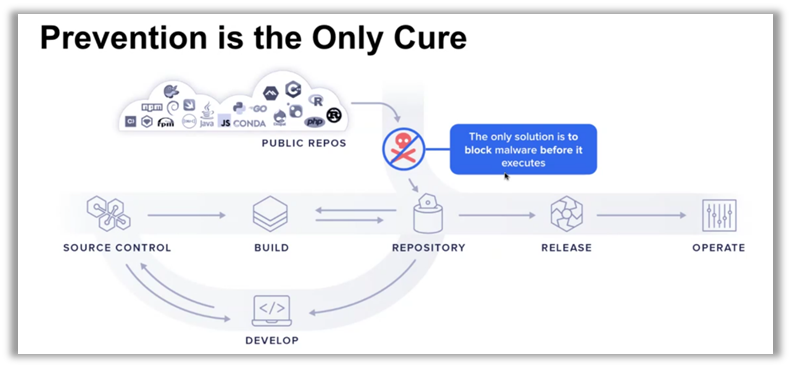
Los componentes de código abierto, omnipresentes en las cadenas de suministro de software modernas, se han convertido en un importante vector de ataque para los ciberdelincuentes. Ilkka Turunen, director técnico de campo de Sonatype, ha destacado el auge del malware oculto en estos componentes. Estos ataques se integran directamente en los sistemas de información, a menudo sin ser detectados por las medidas de seguridad tradicionales. Es fundamental comprender que las soluciones reactivas ya no son suficientes; la prevención proactiva es ahora una necesidad imperiosa.
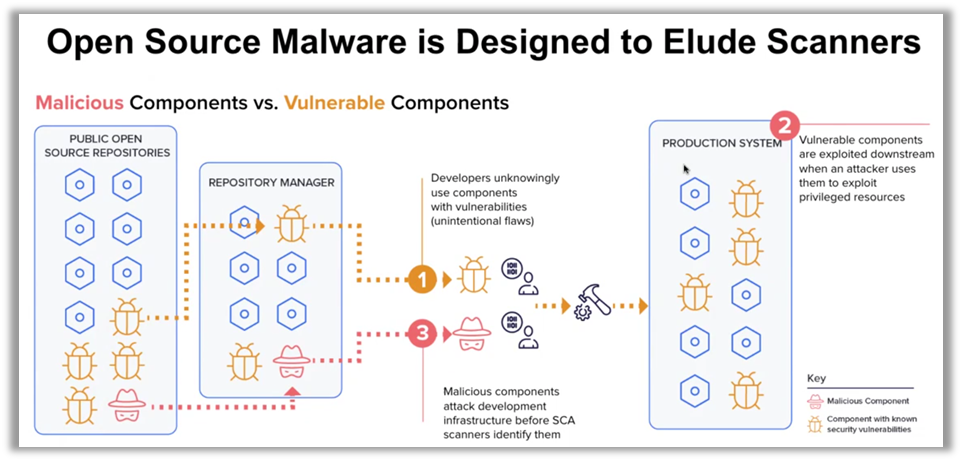
Las cifras hablan por sí solas: alrededor del 50 % de los repositorios de código abierto sin proteger contienen paquetes maliciosos. Esto pone de manifiesto una vulnerabilidad fundamental en la forma en que las empresas gestionan sus cadenas de suministro. Para hacer frente a esta amenaza, las organizaciones deben replantearse su enfoque, incorporando una vigilancia continua y estrategias de prevención mucho antes de que comiencen los ciclos de desarrollo.
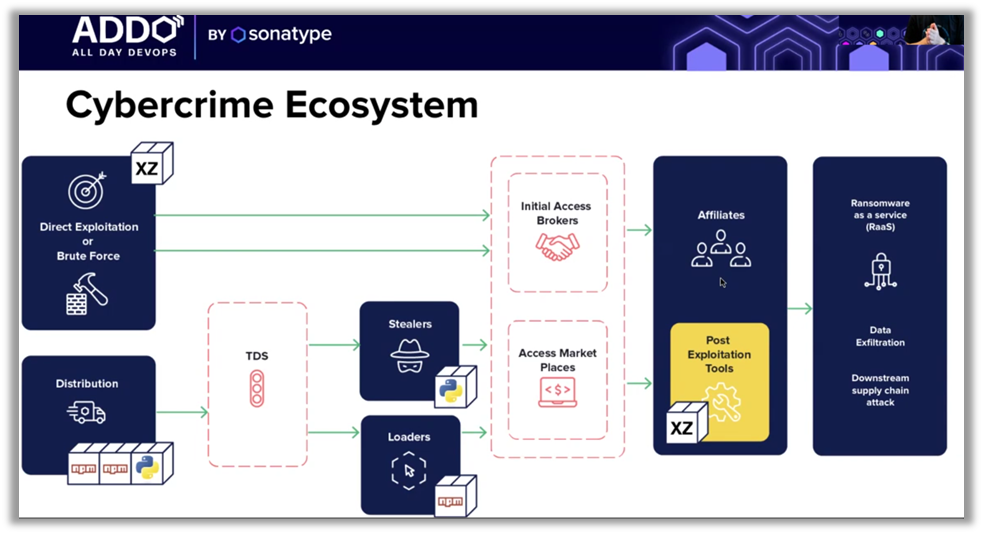
«La seguridad de la cadena de suministro de software no consiste solo en corregir vulnerabilidades, sino en prevenir los ataques antes incluso de que se produzcan.»🚨 - Ilkka Turunen
Modernizar la infraestructura con la microinfraestructura
La transición hacia una arquitectura de microservicios ha supuesto un paso importante para descentralizar el desarrollo de software y hacerlo más ágil. Sin embargo, la infraestructura subyacente no siempre ha seguido este ritmo. Pawel Piwosz, de Tameshi, propone el concepto de «microinfraestructura» para adaptar la infraestructura a la modularidad de los microservicios, lo que hace que cada servicio sea más autónomo, flexible y resistente.
Esto implica una transformación profunda en la que cada servicio cuenta con una infraestructura dedicada, diseñada específicamente para satisfacer sus necesidades particulares. Al permitir unainfraestructura modular, este enfoque refuerza no solo la resiliencia, sino también la eficiencia operativa global.

Este modelo de microinfraestructura también tiene como objetivo mejorar la agilidad de la organización, al permitir que los equipos de desarrollo implementen y modifiquen la infraestructura de forma rápida e independiente. En definitiva, la microinfraestructura es una respuesta directa a las limitaciones de las infraestructuras monolíticas tradicionales, ya que ofrece una mayor capacidad de reacción ante los cambios y una mayor capacidad para adaptarse a las exigencias del mercado.
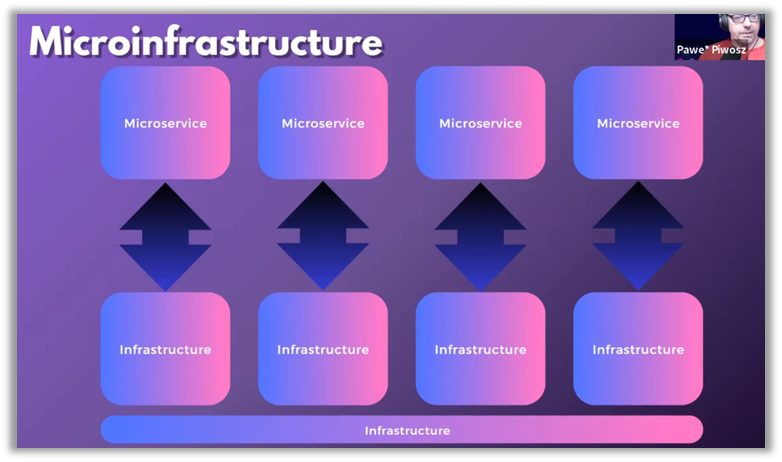
«La infraestructura debería ser tan flexible y ligera como los servicios a los que da soporte.»🛠️ - Pawel Piwosz
Plataformas de desarrollo internas y operadores de Kubernetes
Las plataformas de desarrollo internas (IDP) se han convertido en un elemento esencial para simplificar el trabajo de los desarrolladores y mejorar su productividad. George Hantzaras y Dan McKean, de MongoDB, han destacado la importancia de los operadores de Kubernetes en esta transformación. Estos operadores permiten una gestión más eficaz de las aplicaciones complejas, al facilitar configuraciones estandarizadas y reducir la carga cognitiva de los equipos de desarrollo.
Los operadoresKubernetes facilitan la creación de plataformas robustas capaces de soportar una gran variedad de servicios, al tiempo que mantienen la flexibilidad necesaria para el buen funcionamiento de los sistemas. Automatizan las tareas operativas habituales, como el escalado de aplicaciones, la gestión de actualizaciones y el control del estado de los servicios, lo que permite a los desarrolladores centrarse en escribir código en lugar de en tareas administrativas repetitivas.
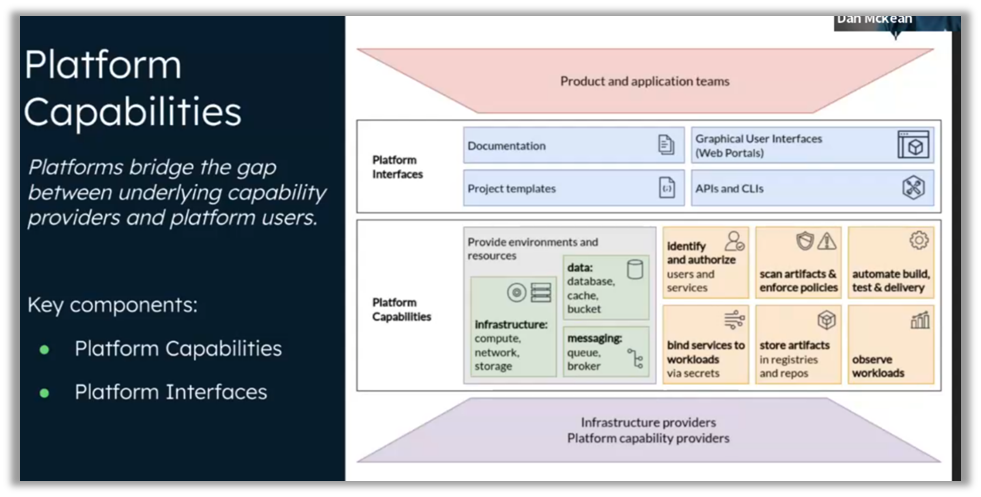
Al combinar estos operadores con soluciones GitOps, las empresas también pueden aprovechar un modelo de gestión declarativo, lo que garantiza la coherencia y la reproducibilidad de las implementaciones. ArgoCD, por ejemplo, permite gestionar el estado de la infraestructura y las aplicaciones a través de configuraciones almacenadas en Git, lo que garantiza un control de versiones claro y facilita la reversión a estados anteriores en caso de problemas. Esto no solo reduce los errores humanos, sino que también mejora la transparencia y la colaboración entre los equipos.
El uso de operadores de Kubernetes también favorece la escalabilidad del IDP, ya que cada operador puede diseñarse específicamente para satisfacer las necesidades de los distintos servicios o entornos. Esto permite una personalización precisa y una gestión optimizada de los recursos, lo que garantiza que la infraestructura se mantenga ágil y preparada para adaptarse a los rápidos cambios en los requisitos empresariales.
«Los operadores de Kubernetes son la clave para convertir Kubernetes en una auténtica plataforma de plataformas».🔧 - George Hantzaras
Ingeniería de plataformas: lecciones aprendidas
Geert van der Cruijsen, de Xebia, compartió su experiencia sobre los errores habituales que suelen producirse en la implementación de plataformas de desarrollo. La ingeniería de plataformas puede ser una potente fuente de eficiencia, pero solo si se evitan las trampas habituales. Entre los errores más frecuentes se encuentran la falta de consideración de las necesidades de los desarrolladores, la formación de equipos inadecuados y la implementación de una plataforma impuesta a los usuarios en lugar de diseñada para ellos.

Uno de los principales errores es tratar la plataforma como una infraestructura técnica sin tener en cuenta la experiencia de usuario de los desarrolladores. Una plataforma eficaz debe concebirse como un producto, con los desarrolladores como clientes. Esto implica recabar constantemente opiniones, perfeccionar las funcionalidades y garantizar que la plataforma se adapte a las necesidades cambiantes de los equipos. Geert van der Cruijsen insiste en la importancia de no caer en la trampa de «constrúyelo y vendrán»: una plataforma, por muy eficaz que sea técnicamente, solo será adoptada si aporta un valor añadido real al día a día de los usuarios.
Además, la composición de los equipos encargados del desarrollo y el mantenimiento de las plataformas es fundamental. Cambiar el nombre de un equipo existente de DevOps o de ingeniería en la nube por el de «equipo de plataforma» sin ajustar su misión y sus competencias no funciona. Un equipo de plataforma debe estar estructurado para centrarse en la creación de productos destinados a los equipos de desarrollo, facilitando su trabajo sin implicarse directamente en las operaciones diarias.

Imponer una plataforma, en lugar de que se adopte de forma natural, es también un error habitual. Se debe animar a los desarrolladores a utilizar la plataforma, no obligarlos. Esto pasa por crear un alto valor percibido, eliminar las fricciones e implementar soluciones que respondan a los problemas reales a los que se enfrentan los desarrolladores. De lo contrario, surgirán iniciativas paralelas y sistemas de «TI en la sombra», lo que hará que la plataforma oficial resulte ineficaz.

Por último, es fundamental medir el retorno de la inversión (ROI) y analizar los puntos de fricción. El éxito de una plataforma no se mide únicamente por su implementación, sino por el impacto que tiene en la productividad de los desarrolladores, la rapidez de las entregas y la calidad del software producido.
Esto implica utilizar métricas como el tiempo de ciclo, la tasa de adopción y la satisfacción de los desarrolladores, con el fin de comprender qué funciona bien y qué aspectos deben ajustarse.
«Una plataforma que no responde a las necesidades reales de sus usuarios se convierte en un obstáculo en lugar de un impulsor.»🚧 - Geert van der Cruijsen
Hacia plataformas antifrágiles
Manuel Pais, autor de «Team Topologies», abordó la idea de una plataforma antifrágil: una plataforma que no solo sobrevive a las crisis, sino que sale fortalecida de ellas. Para que una plataforma sea antifrágil, es necesario diseñarla de manera que pueda adaptarse y fortalecerse ante los imprevistos económicos y organizativos. Esto implica demostrar constantemente su valor a los usuarios, no solo a nivel interno, sino también en toda la organización.
Los pilares de una plataforma de este tipo incluyen la confianza interna y externa, así como el intercambio de experiencias positivas. Manuel Pais destaca la importancia de medir no solo la adopción de la plataforma, sino también la satisfacción de los usuarios y la fiabilidad de los servicios prestados.
La creación de una plataforma antifrágil comienza por el establecimiento de una cultura de colaboración y comunicación transparente. Se debe animar a los equipos a señalar los problemas, a probar soluciones y a aprender de los errores, con el fin de transformar los posibles fracasos en oportunidades de mejora. Al cultivar esta capacidad de sacar partido de las perturbaciones, las plataformas no solo se vuelven resilientes, sino que también son capaces de salir fortalecidas ante los retos.
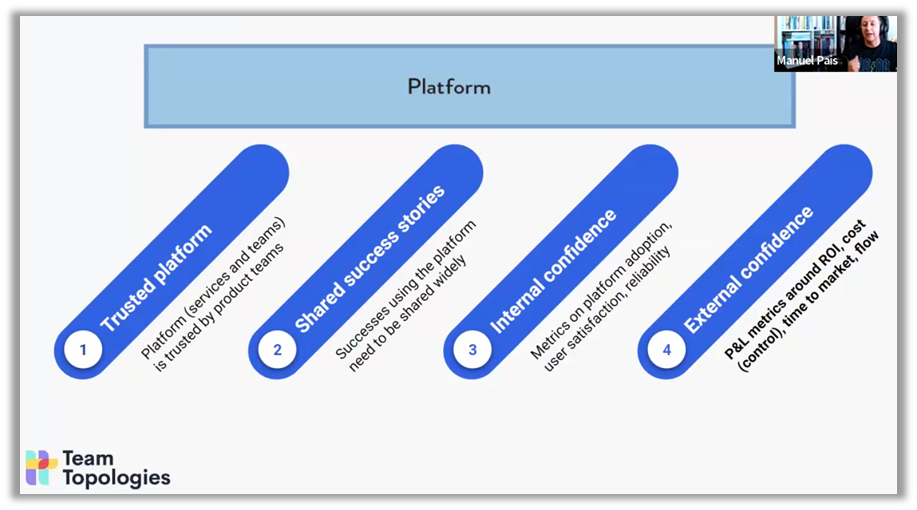
Otro aspecto fundamental es la capacidad de iterar rápidamente y evolucionar. Esto requiere el uso de métricas claras para evaluar el rendimiento, como la fiabilidad, la adopción y la satisfacción de los usuarios. Estos indicadores permiten tomar decisiones fundamentadas para ajustar las funcionalidades y responder a las necesidades cambiantes de los equipos de desarrollo. Manuel Pais también recomienda compartir ampliamente las historias de éxito —ejemplos concretos en los que la plataforma ha ayudado a un equipo a resolver un problema o a ganar en eficiencia— con el fin de reforzar la confianza en el valor de la plataforma.

En términos de gobernanza, una plataforma antifrágil debe estar respaldada por procesos que favorezcan la flexibilidad en lugar de la rigidez. En lugar de imponer normas estrictas, se trata de proporcionar directrices que permitan a los equipos innovar sin dejar de estar alineados con los objetivos generales de la organización. Esto crea un entorno en el que los equipos tienen libertad para experimentar al tiempo que se minimizan los riesgos, reforzando así la solidez de la plataforma.
«Una plataforma antifrágil mejora y prospera ante los retos.»💪 - Manuel Pais
La evolución de las cadenas de suministro de software: oportunidades y retos
La adopción masiva del código abierto ha transformado radicalmente las cadenas de suministro de software durante la última década. Las ventajas son numerosas: una aceleración del desarrollo, una reducción de los costes y el acceso a una comunidad mundial de innovadores. Sin embargo, esta transformación también ha ampliado la superficie de ataque, exponiendo a las empresas a nuevos riesgos relacionados con la seguridad de sus dependencias de código abierto. Brian Fox, director técnico de Sonatype, puso de relieve estos retos durante su presentación, subrayando hasta qué punto la creciente complejidad de las cadenas de suministro supone un desafío considerable para los equipos de desarrollo y seguridad.
Fox también ha compartido los resultados del décimo informe anual sobre el estado de la cadena de suministro de software de Sonatype. Este informe destaca un aumento del 1466 % en la frecuencia de publicación de paquetes de código abierto durante la última década, lo que ilustra la rapidez con la que evoluciona el código abierto. Paralelamente, el MTTR (tiempo medio de reparación) ha experimentado un aumento del 800 %, pasando de 50 a 400 días en solo siete años, mientras que el número de CVE (vulnerabilidades y exposiciones comunes) se ha disparado de 2 000 a casi 30 000 en 25 años, lo que supone un aumento de casi el 1 500 %.
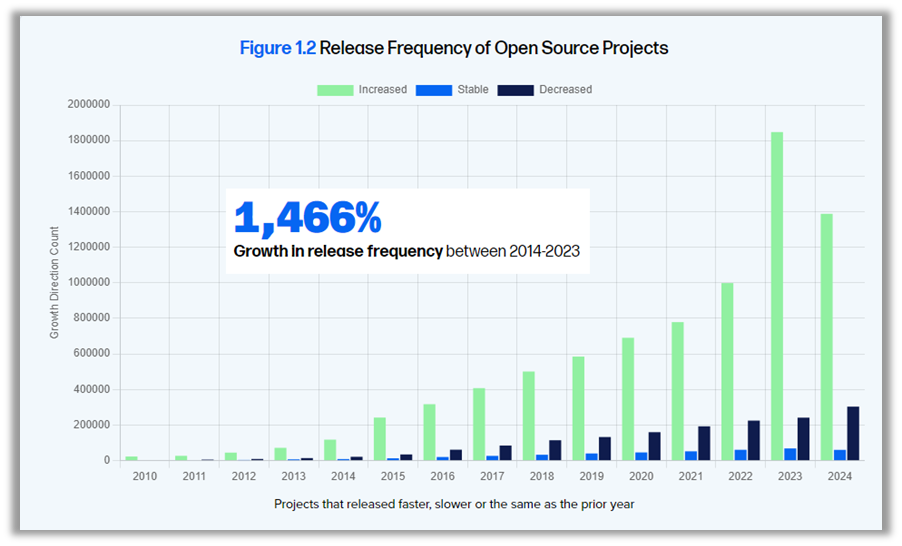
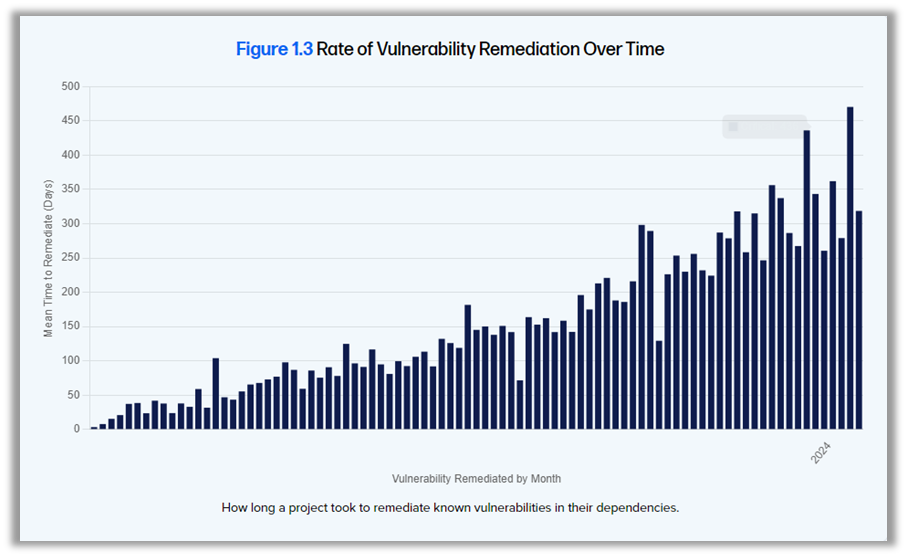
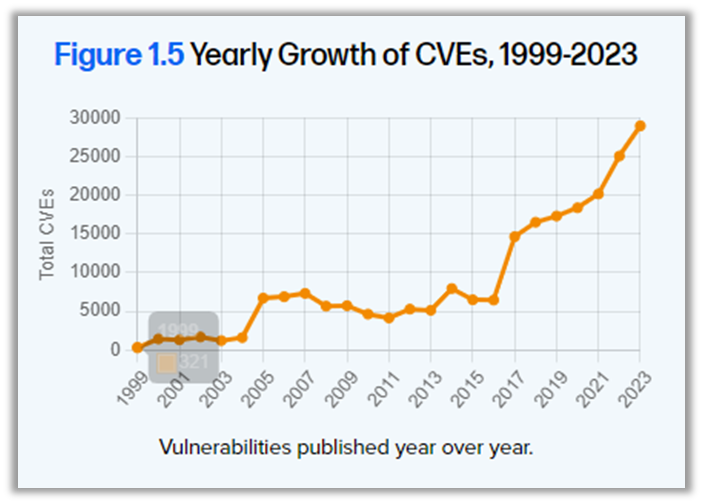
Estas cifras ponen claramente de manifiesto la magnitud de los retos a los que se enfrentan las empresas en materia de seguridad de la cadena de suministro. De hecho, el 96 % de los proyectos de código abierto vulnerables no se han actualizado, lo que supone una oportunidad clara para que los ciberatacantes aprovechen estas vulnerabilidades.
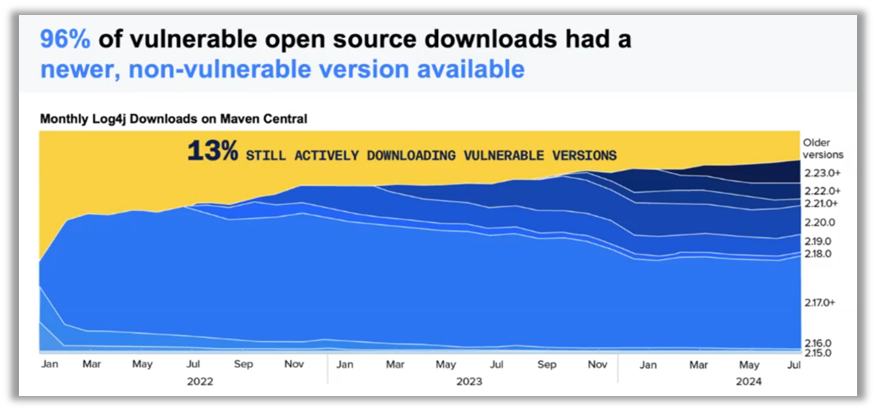
Para hacer frente a estos retos, Brian Fox ha destacado la importancia de replantearse la gestión de las cadenas de suministro. No se trata solo de reaccionar ante las vulnerabilidades a posteriori, sino de integrar prácticas de seguridad desde el inicio del ciclo de desarrollo, un concepto conocido como «shift left».
Es necesario promover una cultura de la seguridad entre los equipos de desarrollo. Esto significa que es fundamental responsabilizar a los desarrolladores y animarlos a considerar la seguridad como parte integrante de su trabajo diario. Esto pasa por una estrecha colaboración entre los equipos de desarrollo y de seguridad, procesos rigurosos de gobernanza y la adopción de herramientas que faciliten la detección y corrección de vulnerabilidades sin interrumpir el flujo de trabajo.
Las empresas deben participar activamente en la mejora de la seguridad de los componentes que utilizan, en lugar de limitarse a consumir software de código abierto. Al contribuir a proyectos de código abierto, notificar vulnerabilidades y compartir parches, las organizaciones refuerzan no solo supropia seguridad, sino también la detodo el ecosistema. Este enfoque colaborativo es esencial para reducir la superficie de ataque y reforzar la resiliencia de las cadenas de suministro.
También es fundamental implementar procesos de validación continua en los flujos de trabajo de integración y despliegue (CI/CD). Estos procesos deben incluir auditorías periódicas de los componentes de terceros y una verificación automatizada de las dependencias en cada etapa del ciclo de desarrollo. Esto garantiza que las nuevas versiones del software incorporen componentes seguros y actualizados, reduciendo así la probabilidad de introducir vulnerabilidades explotables.
Las herramientas de análisis de composición de software (SCA) no solo pueden identificar vulnerabilidades, sino que también recomiendan versiones más seguras, lo que facilita la gestión proactiva de las dependencias.
En conclusión, la evolución de las cadenas de suministro de software de código abierto ofrece importantes oportunidades, como la rapidez y la innovación colaborativa, pero también plantea retos importantes en materia de seguridad. Para sacar el máximo partido de ellas y minimizar los riesgos, es esencial adoptar un enfoque proactivo de la seguridad, reforzar la gobernanza de las dependencias y promover una cultura de seguridad compartida entre los equipos. Combinando herramientas de vanguardia, una colaboración activa y una vigilancia continua, las empresas pueden garantizar la resiliencia y la fiabilidad de su software en un panorama de amenazas cada vez más complejo.
«La creciente complejidad de las cadenas de suministro exige estrategias proactivas para garantizar la seguridad y la resiliencia.»🔒 - Brian Fox
Aplicaciones nativas en la nube y resiliencia
Con las arquitecturas nativas de la nube, la escalabilidad y la flexibilidad se convierten en características inherentes, pero la resiliencia sigue siendo un reto importante. Ricardo Castro, de Blip/FanDuel, presentó diversas estrategias para diseñar aplicaciones capaces de resistir las interrupciones del servicio. Estas estrategias incluyen implementaciones «Blue/Green», implementaciones «canary» y el uso de «Dark Launches» para minimizar los riesgos durante las puestas en producción.
Las implementaciones Blue/Green permiten mantener dos entornos paralelos, lo que garantiza una transición fluida durante las actualizaciones. Esto reduce las interrupciones del servicio y facilita la reversión en caso de que surja algún problema. Por su parte, las implementaciones canary ofrecen un enfoque gradual, al implementar las nuevas versiones en un subconjunto de usuarios con el fin de identificar posibles problemas antes de su puesta en producción generalizada. Los lanzamientos oscuros permiten probar nuevas funcionalidades en producción sin exponerlas directamente a los usuarios, lo que ofrece la posibilidad de recopilar datos reales al tiempo que se limitan los riesgos.
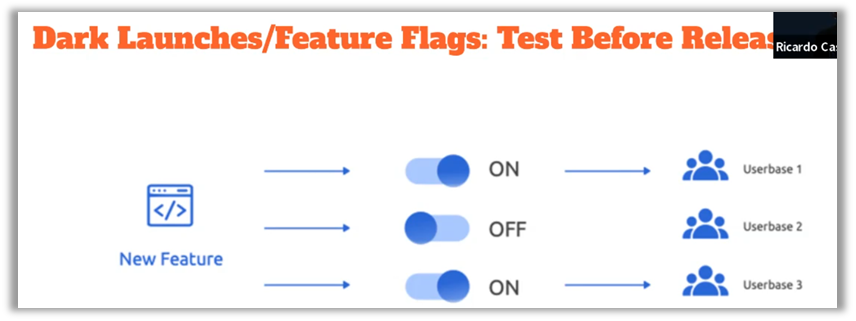
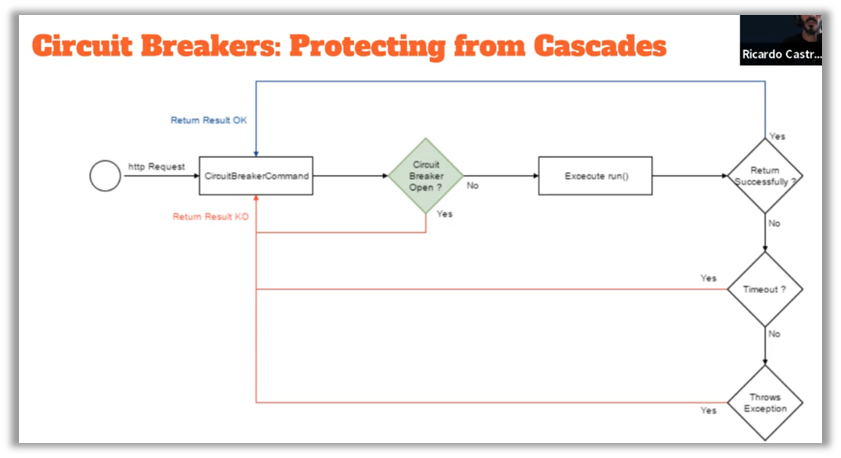
Los patrones de resiliencia en tiempo de ejecución, como los Circuit Breakers y los Bulkheads, también son fundamentales para garantizar la solidez de las aplicaciones. Los Circuit Breakers actúan como disyuntores al desactivar temporalmente los servicios defectuosos, evitando así que los errores se propaguen por todo el sistema. Los bulkheads, inspirados en los mamparos de los barcos, aíslan diferentes partes del sistema para limitar el impacto de los fallos en otros componentes. Estas prácticas son esenciales para evitar que un fallo aislado se convierta en una caída completa del sistema.
«Para crear aplicaciones nativas de la nube resilientes se necesita una combinación de estrategias de implementación inteligentes y mecanismos de protección adecuados.»☁️⚡ - Ricardo Castro
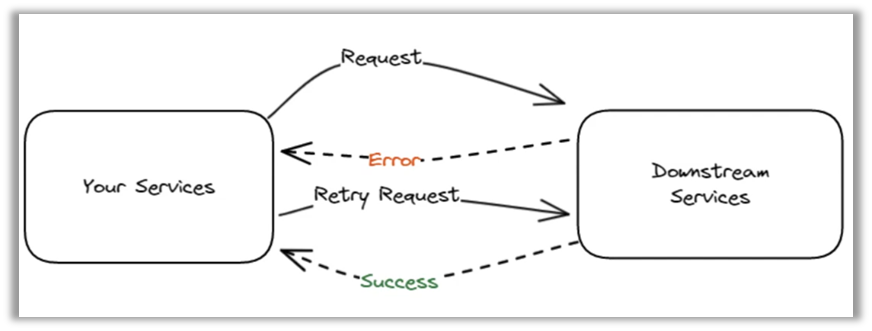
Otra estrategia clave es el uso de tiempos de espera y reintentos, que permiten gestionar los fallos intermitentes limitando el tiempo de espera para obtener una respuesta y volviendo a intentar las operaciones fallidas. Esto ayuda a evitar bloqueos prolongados que pueden afectar al rendimiento general. Además, la limitación de tasa es una técnica importante para controlar el número de solicitudes dirigidas a un servicio, evitando así una sobrecarga que podría degradar la calidad del servicio.
Ricardo Castro también hizo hincapié en la importancia de la observabilidad en las arquitecturas nativas de la nube. Para construir sistemas resilientes, es imprescindible disponer de una visibilidad completa del estado de los servicios, gracias a herramientas de monitorización, registro y rastreo distribuido. Estas herramientas no solo permiten detectar rápidamente los problemas, sino también identificar su origen y aplicar medidas correctivas eficaces.
Por lo tanto, la resiliencia de las aplicaciones nativas de la nube se basa en una combinación de estrategias de implementación inteligentes, mecanismos de protección en tiempo de ejecución y una mayor observabilidad. Estos elementos, cuando están bien integrados, permiten garantizar la continuidad del servicio y una experiencia de usuario de calidad, incluso ante fallos imprevistos.
Construir un futuro resiliente
La resiliencia de las plataformas y la seguridad del código abierto son retos estratégicos ineludibles para las empresas modernas. En un entorno en el que las amenazas son cada vez más sofisticadas, es esencial adoptar un enfoque proactivo. Esto pasa por una vigilancia continua, la innovación en materia de seguridad y una estrecha colaboración con la comunidad de código abierto, que constituyen herramientas clave para hacer frente a los retos actuales y futuros. Como ha señalado Brian Fox, la seguridad proactiva debe considerarse una inversión estratégica y no un simple coste, ya que permite construir sistemas capaces no solo de resistir las crisis, sino también de prosperar gracias a ellas.
La resiliencia no se limita a la protección frente a las amenazas: también implica la capacidad de aprender y mejorar continuamente ante los incidentes. Esta filosofía se basa en la integración de las mejores prácticas de seguridad a lo largo de todo el ciclo de desarrollo, así como en la implantación de procesos que permitan una reacción rápida y específica ante los ataques. El uso de herramientas de observabilidad, monitorización y análisis en tiempo real es fundamental para garantizar una visibilidad completa del estado de los sistemas, identificar rápidamente los fallos y aplicar correcciones antes de que se conviertan en críticos.
Al garantizar una visibilidad completa de las operaciones y los componentes, las organizaciones pueden identificar no solo los incidentes visibles, sino también las debilidades subyacentes que podrían hacerlas vulnerables a futuros ataques. Las empresas también deben recurrir a la automatización asistida por IA para permitir una respuesta rápida, asignar de manera eficaz los recursos necesarios para la resolución de incidentes y minimizar el impacto en las operaciones que aportan poco valor añadido a la intervención manual humana.
Además, la colaboración con la comunidad de código abierto desempeña un papel fundamental en el desarrollo de esta resiliencia. Al compartir información sobre nuevas amenazas y participar activamente en la mejora de las herramientas de código abierto, las empresas contribuyen a la seguridad colectiva del ecosistema. Esta colaboración fomenta un círculo virtuoso: cada contribución individual refuerza no solo la seguridad de la organización que la realiza, sino también la de toda la comunidad. Esto permite poner en común conocimientos y soluciones, lo cual es especialmente crucial ante las amenazas globales.
«La seguridad proactiva no es un gasto, sino una inversión para crear sistemas antifrágiles que prosperen ante la adversidad». 🔐💡 - Brian Fox
Es hora de que los líderes tecnológicos se pregunten si sus estrategias actuales están a la altura de esta exigencia de resiliencia o si aún hay margen de mejora. 💭
Para quienes deseen profundizar en los temas tratados durante el All Days DevOps 2024, las sesiones grabadas están disponibles bajo demanda, lo que permite volver a ver las intervenciones de los expertos y comprender mejor los retos y las soluciones debatidos. Puede acceder a los vídeos a través de la página web oficial: All Day DevOps.
