

Cuando se desea enviar registros procedentes de diversos entornos a un SIEM, la solución que se suele implementar pasa primero por una plataforma de centralización que servirá como punto único de entrada de datos y de distribución hacia el SIEM, un sistema de archivo legal de registros, diversas herramientas de monitorización, etc. La configuración de esta plataforma de centralización puede resultar rápidamente tediosa a largo plazo: multiplicidad de configuraciones, falta de seguimiento de las evoluciones y modificaciones manuales, retroceso complejo en caso de error, «pruebas en producción», etc. Estos problemas se agravan aún más si la función de centralización recae en varios servidores. Veremos que, al combinar herramientas conocidas de CI/CD con los servicios «ofrecidos» dentro de AWS, podemos abordar estos puntos con relativa facilidad.
Este artículo es un resumen de la experiencia adquirida sobre lo que se ha logrado en el marco de un proyecto y no pretende mostrar una implementación ideal, sino simplemente abordar lo que es posible llevar a cabo partiendo de un sistema ya existente.
Descripción del entorno
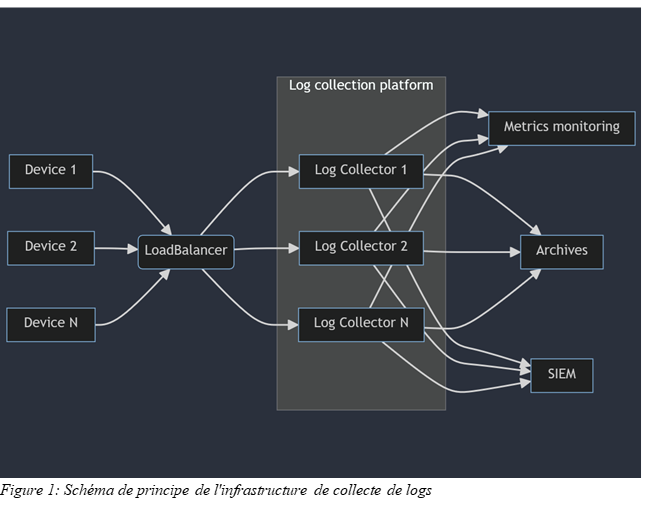
Estructura de la recogida
La centralización de los registros se aloja en AWS en instancias EC2. Estas instancias EC2 se publican al mundo exterior a través de un LoadBalancer de AWS. El LoadBalancer escucha en una serie de puertos UDP o TCP. Todo el tráfico que llega a estos puertos se redirige a las instancias EC2 de recopilación. El LoadBalancer supervisa por sí mismo la disponibilidad de los puertos en las instancias EC2 para determinar a qué instancia o instancias se puede dirigir el flujo.
Nota: la configuración del LoadBalancer queda fuera del alcance de este artículo.
El servicio que se utiliza en las instancias de Log Collector es FluentD. Se trata de una herramienta de código abierto que permite recopilar registros mediante diversos complementos incluidos de forma nativa en la aplicación o desarrollados por la comunidad.
Nota: Aunque aquí hablamos de FluentD, los principios que se abordan en este artículo son válidos también para otras herramientas más tradicionales, como Rsyslog o syslog-ng.
Control de versiones, integración y entrega continua
Es importante que, cada vez que se realice una modificación (creación, eliminación o actualización) en nuestra configuración de recopilación, podamos responder a algunas preguntas:
¿De qué modificación se trata?
¿Quién ha realizado la modificación?
¿Cuándo se produjo ese cambio?
¿Por qué se ha llevado a cabo este cambio?
Almacenar nuestra configuración en un sistema de control de versiones nos permitirá conservar un historial de todos los cambios realizados en nuestra configuración, así como la respuesta a estas cuatro preguntas en forma de metadatos. Combinaremos este sistema de control de versiones con una herramienta de integración y entrega continuas (Continuous Integration/Continuous Delivery, o CI/CD) para automatizar determinadas acciones cuando se realicen cambios en nuestra configuración.
Existen varias herramientas que ofrecen estas funcionalidades, pero nuestra elección recae en GitLab, que integra todo lo que necesitamos y que podemos implementar en el núcleo de nuestra infraestructura.
Protección de la plataforma
El uso de una herramienta de CI/CD puede dar lugar a numerosos riesgos de seguridad, debido a su objetivo de ejecutar un conjunto de comandos dentro de la infraestructura de destino. Cabe pensar, en particular, en la ejecución de código arbitrario que pueda provocar interrupciones del servicio dentro de la plataforma o que pueda divulgar información confidencial, ya sea de forma intencionada (un actor malintencionado que se apodera del sistema de CI/CD) o no (un error de un operador). Por lo tanto, conviene prestar especial atención a esta problemática y ajustar con la mayor precisión posible los permisos de los distintos sistemas implicados.
En el resto del artículo se detallarán los permisos necesarios en cada paso.
Ramas y tuberías
El uso de GitLab para gestionar nuestra configuración nos permite definir desencadenantes de nuestro proceso de CI/CD en función de eventos específicos. Nuestra necesidad será la siguiente:
No es necesario implementar sistemáticamente todos los cambios de configuración que se envían al repositorio Git
En primer lugar, hay que validar un conjunto de cambios en un entorno de integración
Solo se puede autorizar una implementación en producción una vez que los cambios se hayan validado en la fase de integración
Por lo tanto, se aplicará la siguiente política:
La rama «main» del proyecto es el reflejo de la configuración de producción y servirá de base para las implementaciones. Se prohibirá cualquier cambio en tiempo real en esta rama, por lo que se protegerá.
Se creará una rama denominada «integración», que servirá de base para las configuraciones que se vayan a validar. Al igual que en la rama «main», se prohibirá cualquier modificación directa en esta rama, protegiéndola
Se creará una rama para cada conjunto de cambios que se vayan a aplicar a la plataforma de recopilación (por ejemplo, la definición de un nuevo ámbito de recopilación). Una vez que los cambios se consideren finalizados, la rama se «fusionará» con la rama «integración».
Por cada «merge» en la rama «integration», la configuración se implementará en un entorno de integración mediante la activación de un pipeline de CI/CD. Si esta implementación se lleva a cabo sin problemas, el contenido de la rama «integration» se «fusionará» con la rama «main».
Cada vez que se realice una «fusión» en la rama «main», se llevará a cabo una implementación de la configuración en el entorno de producción mediante la activación de un pipeline de CI/CD.
La implementación y la aplicación de la configuración se gestionarán íntegramente mediante un pipeline de CI/CD. La implementación en el entorno de integración o en producción se llevará a cabo exactamente de la misma manera; lo único que variará serán los destinos. Para ello, se utilizará el conceptode entorno dentro de GitLab, que permite definir valores diferentes para una misma variable. También se incorporan otras funcionalidades, como la garantía de que solo se ejecute el trabajo de implementación más reciente para un entorno determinado o el seguimiento de cada implementación.
Implementación de la configuración
Publicación de la configuración
La publicación de la configuración en sí misma se realizará de forma relativamente sencilla, subiendo los archivos de configuración a un bucket de S3. Se podrá distinguir entre las plataformas de producción y de integración utilizando buckets de S3 diferentes o mediante una estructura de directorios diferenciada dentro de un único bucket de S3. Para asegurarnos de no conservar ninguna configuración obsoleta, primero eliminamos el contenido ya presente en el bucket S3 antes de subir la nueva versión.
Para que nuestro CI/CD pueda publicar los archivos de configuración en nuestro bucket de S3, será necesario otorgar a nuestro runner de GitLab permiso para listar, subir y eliminar objetos en el almacenamiento S3. Por lo tanto, habrá que autorizar las siguientes acciones:
s3:PutObject
s3:GetObject
s3:DeleteObject
Lo ideal sería que estas acciones estuvieran autorizadas en los objetos de configuración que vamos a enviar. En este caso, se tratará de
arn:aws:s3:::log-collection-bucket/configuration/integration/*
arn:aws:s3:::log-collection-bucket/configuration/production/*
Aplicación de la configuración en las instancias de recopilación
Ya hemos superado el primer paso: sabemos cómo poner a disposición la configuración que hay que implementar en nuestros servidores de recopilación. Ahora solo queda aplicarla a nuestras instancias de recopilación. En esencia, se trata de descargar los archivos almacenados en nuestro bucket de S3, compararlos con los existentes y, si se detecta alguna diferencia, reiniciar el servicio. También se puede activar una notificación (utilizando AWS SNS, por ejemplo) para avisar a los operadores de si el reinicio del servicio de recopilación se ha realizado con éxito o no.
Ahora se trata de determinar cómo poner en marcha estas operaciones. Dado que nuestras instancias están alojadas en AWS, podemos recurrir a la función «Run Command» del servicio AWS System Manager, que nos permite ejecutar una serie de comandos desde nuestros sistemas. Estas operaciones se ejecutarán en paralelo y, si es necesario, podremos aprovechar el registro de auditoría de AWS CloudTrail.
Adaptamos la configuración de nuestro CI/CD en consecuencia añadiendo la llamada al comando «SendCommand» de AWS System Manager. En nuestro ejemplo, la ejecución de la lógica de reinicio del servicio de recopilación se lleva a cabo mediante un script de Python ubicado directamente en nuestros sistemas en la ruta «/opt/log_collection/deploy.py» y que toma como único parámetro la dirección del bucket S3 que contiene la configuración que se debe aplicar.
Desde el punto de vista de la seguridad, la llamada a AWS System Manager puede resultar problemática, ya que permitimos la ejecución de comandos de forma remota en nuestros sistemas. Por lo tanto, habrá que asegurarse de que nuestro CI/CD solo tenga permisos para ejecutar comandos a través de System Manager dirigidos a nuestros colectores de registros. Suponiendo que hayamos etiquetado las instancias que componen nuestra plataforma de recopilación como «InstanceRole: LogCollection», la definición de una ResourcePolicy como la siguiente, que permite el uso de la acción «ssm:SendCommand», nos garantizará que solo el CI/CD pueda iniciar operaciones a través de System Manager hacia las instancias de recopilación de registros.
Para una seguridad más avanzada, todo dependerá del formato que adopte el script de implementación: si se trata de un script que se ejecuta directamente en los sistemas de destino o si se utiliza un documento SSM.
¿Y los secretos?
Como sabemos, guardar secretos directamente en un repositorio Git es una práctica muy desaconsejable. Por desgracia, nuestra configuración puede requerir el uso de secretos: certificados y claves privadas para habilitar el cifrado de una conexión TCP, credenciales para acceder a un servicio de almacenamiento de archivos, claves API para acceder a un servicio web, etc. Por lo tanto, es necesario asegurarnos de que ninguna de estas informaciones se encuentre «en plano» en nuestra configuración. Para ello, utilizaremos el servicio AWS Secret Manager, que nos permite almacenar nuestros secretos para ponerlos a disposición para diversos usos.
Credenciales y claves API
La mayoría de los servicios de recopilación pueden acceder a variables de entorno. Por lo tanto, vamos a aprovechar esta funcionalidad para transmitir nuestras diferentes contraseñas, frases de contraseña o claves API a nuestro servicio de recopilación.
En el caso de FluentD, el archivo de entorno se encuentra en la ruta «/etc/sysconfig/td-agent» y debe contener las variables de entorno que se cargarán al iniciar el servicio en el formato «export VAR1="foo"». Por lo tanto, nuestro script de implementación de la configuración se encargará de rellenar este archivo con los secretos publicados en AWS Secret Manager. Al igual que con el resto de la configuración, se generará un archivo de entorno temporal que se comparará con el archivo actual. Si se detectan diferencias, será necesario reiniciar el servicio de recopilación.
Para generar este archivo de entorno, vamos a crear un archivo secrets.conf en nuestro repositorio. Cada línea de este archivo hará referencia a un secreto y tendrá el siguiente formato: «env#var_name#aws_secret_arn».
« env » es aquí una palabra clave que nos servirá más adelante para distinguir entre las entradas de este archivo que son variables de entorno y las que son archivos
«var_name» es el nombre de la variable de entorno tal y como lo espera el servicio de recopilación
«aws_secret_arn» es el identificador del secreto almacenado en AWS Secret Manager
Certificados y claves privadas
Dependiendo de los métodos de recopilación elegidos, es posible que sea necesario implementar certificados y/o claves privadas, ya sea para permitir la recepción de flujos cifrados mediante TLS o para permitir la autenticación en servicios remotos mediante el intercambio de claves. Podemos almacenar estos archivos en la carpeta «/etc/td-agent/certs/».
La lógica que se aplica aquí es equivalente a la que se habría podido implementar para los secretos almacenados en el entorno, por lo que aprovecharemos el archivo «secrets.conf» creado anteriormente y añadiremos líneas con el formato «file#file_name.pem#aws_secret_arn». La diferencia radica en que, en lugar de almacenar los secretos en forma de variables de entorno en un único archivo, copiaremos el contenido del secreto de AWS a un archivo ubicado en una carpeta temporal y nombrado según las indicaciones contenidas en el archivo secrets.conf. Una vez que todos los secretos se hayan transferido al servidor local, si existen diferencias entre la carpeta temporal y la carpeta utilizada por el servicio, se eliminará el contenido de esta carpeta de destino, se copiarán todos los datos de la carpeta temporal a esta y se permitirá el reinicio del servicio de recopilación.
Seguridad
Los archivos mencionados anteriormente son especialmente sensibles debido a su contenido. Es necesario controlar rigurosamente el acceso a ellos para garantizar que solo el servicio de recopilación pueda acceder a ellos. Por lo tanto, añadiremos a nuestro script de implementación los comandos adecuados para asegurarnos de que el propietario del archivo «/etc/sysconfig/td-agent» y de la carpeta «etc/td-agent/secrets» y su contenido sea efectivamente el usuario con el que se inicia nuestro servicio de recopilación, y para garantizar que solo el propietario de estos archivos pueda leerlos.
Además, será necesario conceder permisos a las instancias de EC2 que alojan el servicio de recopilación para que puedan leer y descifrar los secretos almacenados en AWS Secret Manager. También será necesario limitar estrictamente este permiso únicamente a los secretos necesarios para la recopilación, por ejemplo, adoptando una convención de nomenclatura para nuestros secretos.
Implementación de pruebas
Ahora sabemos cómo implementar nuestra configuración y reiniciar la recopilación de registros si es necesario, en caso de que haya que tener en cuenta cambios en nuestra plataforma de integración o en nuestra plataforma de producción. Si una configuración no es válida, nuestra plataforma de integración no podrá reiniciarse, lo que nos evitará implementar en producción y dejar nuestra recopilación fuera de servicio. Sin embargo, lo mejor sería darnos cuenta de que nuestra configuración no es válida antes de implementarla en la integración. Para ello, vamos a implementar una lógica que nos permita probar y validar nuestra configuración cada vez que se publique una modificación en nuestro repositorio.
Por lo tanto, vamos a añadir una etapa a la configuración de nuestro CI/CD a la que llamaremos simplemente «Test», así como un trabajo asociado a ella que se ejecutará de forma sistemática. Esta tarea se cargará en un entorno en el que FluentD estará preinstalado (el uso de una imagen Docker resulta especialmente útil en este caso) y ejecutará los mismos comandos que el script de implementación, con una excepción. FluentD es capaz de iniciar una comprobación de su configuración y detenerse. Si se produce un error de configuración, el comando falla y devuelve un código de salida distinto de cero. Por lo tanto, en el script de prueba sustituiremos el comando de reinicio del servicio por el comando de validación de la configuración.
A partir de ahora, si se produce un error al generar la configuración (por ejemplo, si no se puede recuperar un secreto) o si la configuración es inválida (variable de entorno no definida, error en la sintaxis del archivo de configuración), la tarea fallará, lo que detendrá el avance de nuestro CI/CD y, por lo tanto, bloqueará las implementaciones en los entornos de integración o de producción. También será posible configurar el proyecto en GitLab para bloquear cualquier solicitud de fusión mientras falle el CI/CD, lo que obligará de facto a que exista una configuración sintácticamente correcta en las ramas «integration» y «main» (y, por lo tanto, en nuestros entornos de integración y producción).
Es importante señalar que el sistema en el que se ejecutará nuestro script de prueba deberá tener los mismos permisos en AWS Secrets Manager que nuestras instancias EC2 de integración y producción. De hecho, parte de las pruebas consiste en recuperar los secretos para garantizar una configuración correcta.
Seguridad en la integración y la entrega continuas
Ahora sabemos cómo implementar nuestra configuración en todos nuestros sistemas, al tiempo que gestionamos los distintos secretos necesarios para recopilar correctamente nuestros registros. Para ello, hemos tenido que conceder una serie de permisos en nuestro entorno de AWS tanto a nuestros sistemas de destino como a nuestro servidor que ejecuta nuestro CI/CD. En consecuencia, el secuestro del CI/CD puede provocar el compromiso del sistema de recopilación de registros o el compromiso de los secretos que se utilizan en él, al modificar los comandos ejecutados durante las implementaciones.
Por lo general, la configuración de CI/CD se incluye en el repositorio del proyecto. Los usuarios con permisos para modificar el contenido del proyecto también podrán modificar la configuración de CI/CD. Estos cambios se supervisarán, como es lógico, al igual que cualquier otra modificación del proyecto, pero podrían detectarse demasiado tarde. Por lo tanto, es necesario bloquear cualquier modificación de la configuración de CI/CD de nuestro proyecto.
Por lo tanto, se plantean dos opciones:
Al mantener la configuración de CI/CD dentro del proyecto, podemos configurar GitLab para que defina los propietarios del código, de modo que cada modificación del archivo .gitlab-ci.yml (el archivo predeterminado que contiene la configuración de CI/CD) sea validada y aprobada por una persona de confianza
trasladando el archivo .gitlab-ci.yml a un proyecto externo y modificando la configuración de nuestro proyecto para utilizar ese archivo externo. De este modo, los miembros de nuestro proyecto de configuración de recopilación de registros ya no podrán acceder a la configuración, ni para leerla ni para escribir en ella. Esta solución nos permite así respetar el principio del privilegio mínimo, ya que el equipo encargado de la configuración de la recopilación de registros no necesita necesariamente conocer cada paso seguido para implementar dicha configuración.
Conclusión
Es perfectamente posible diseñar un sistema que permita implementar de forma segura la configuración necesaria para recopilar los datos críticos para un SIEM en paralelo en varios «servidores». No obstante, las medidas aquí expuestas constituyen solo un punto de partida para construir un sistema más fiable y seguro. Entre las medidas adicionales que se pueden considerar, se encuentran:
la aplicación dinámica de permisos en los distintos sistemas, de modo que nuestras instancias solo puedan acceder a los secretos o al bucket de S3 que contiene su configuración de referencia durante una implementación
aplicación de una política de no repudio de las modificaciones implementadas mediante el rechazo de las modificaciones que no estén firmadas digitalmente
la realización de revisiones de cualquier modificación en nuestro proyecto con el fin de limitar los riesgos de vulnerabilidades (intencionadas o no)
Dado que aún no hemos podido poner en práctica este tipo de medidas, estas podrían ser objeto de un futuro artículo.



