
Adaptive Telemetry : moins de bruit, plus de valeur
Maîtriser les coûts de l'observabilité
L'un des défis majeurs des équipes techniques aujourd'hui est le coût croissant de l'observabilité. Plus une infrastructure est grande, plus le volume de données collectées, métriques, logs, traces explose, et avec lui la facture.
GrafanaCloud répond à ce problème avec l'Adaptive Telemetry, une approche qui consiste à ne collecter que les données réellement utiles. Lancée progressivement depuis 2023, elle couvre désormais :
- Les métriques (depuis 2023)
- Les logs (depuis 2024)
- Les traces et les profils (depuis 2025)
L'idée est simple : plutôt que de tout stocker et trier ensuite, le système évalue en temps réel si une donnée mérite d'être conservée, en se basant sur des critères de pertinence (anomalies, latences, erreurs…).
Dans le même esprit, Grafana annonce Grafana Focus, un projet développé en collaboration avec la FinOps Foundation, visant à unifier et standardiser la lecture des factures d'observabilité. Un outil attendu par les équipes FinOps et les DSI qui peinent à réconcilier les coûts d'infrastructure avec leur usage réel.
À noter : il n'existe pas encore de provider Terraform officiel pour ces nouveaux outils.
Autre nouveauté orientée grands comptes : Grafana Bring Your Own Cloud. Contrairement au modèle SaaS classique où les données transitent par les serveurs de Grafana, cette offre managée permet aux grandes organisations de stocker leurs données directement dans leur propre tenant cloud. Un modèle qui répond aux exigences de souveraineté des données et aux politiques de sécurité strictes de certaines industries.
Réduire la complexité : Grafana devient plus accessible
Grafana est un outil extrêmement puissant, mais historiquement complexe à prendre en main. Comme l'a résumé un intervenant : "Utiliser Grafana, c'est comme travailler le bois on peut tout faire, mais on part de zéro."
Pour changer cela, plusieurs initiatives ont été présentées :
- Des dashboards prêts à l'emploi pour les cas d'usage les plus courants : supervision Linux, Kubernetes, applications web... Plus besoin de construire ses tableaux de bord de A à Z.
- Database Observability : une nouvelle brique dédiée à l'analyse fine des bases de données. Elle permet de visualiser et d'analyser les requêtes SQL, d'identifier les requêtes lentes, et de comprendre l'impact de la BDD sur les performances globales d'une application.
- Knowledge Graph : une plateforme horizontale qui cartographie automatiquement les services, leurs dépendances et leurs interactions. Elle permet de répondre à des questions comme "Quels services sont impactés si cette base de données tombe ?" ou "Quel est le chemin critique entre ces deux microservices ?".
- Insights : un moteur de détection automatique des anomalies latences inhabituelles, changements de configuration, comportements anormaux sans avoir à configurer manuellement des règles d'alerte pour chaque cas.
- Root Cause Analysis Workbench : un portail centralisé qui agrège l'ensemble des problèmes détectés et propose des actions correctives. L'objectif est de donner aux équipes une vue unifiée des incidents en cours, quel que soit leur origine.
- Fleet Manager & Instrumentation Hub : via un agent léger, il est possible de superviser l'ensemble des ressources compute containers, instances EC2, fonctions Lambda, services managés et de centraliser toutes les données dans Grafana Cloud.
Grafana Assistant : l'IA au service de tous les profils
C'est sans doute l'annonce la plus attendue et la plus discutée de cet ObservabilityCON. Grafana Assistant est l'assistant IA intégré directement dans la plateforme Grafana Cloud. Disponible officiellement depuis janvier 2026, il est proposé au tarif de 20 $/utilisateur/mois.
Une adoption déjà massive
Avec 17 000 utilisateurs quotidiens, l'engouement est réel. Les retours de la communauté sont très positifs, et de nouveaux cas d'usage émergent chaque jour lors des phases de POC. Un exemple particulièrement frappant a été cité : lors d'un POC, un incident s'est produit en production et c'est l'assistant qui a identifié la root cause avant même que les équipes aient eu le temps de se mobiliser.
Pour qui ?
L'assistant a été conçu pour être utile à tous les profils, pas seulement aux experts :
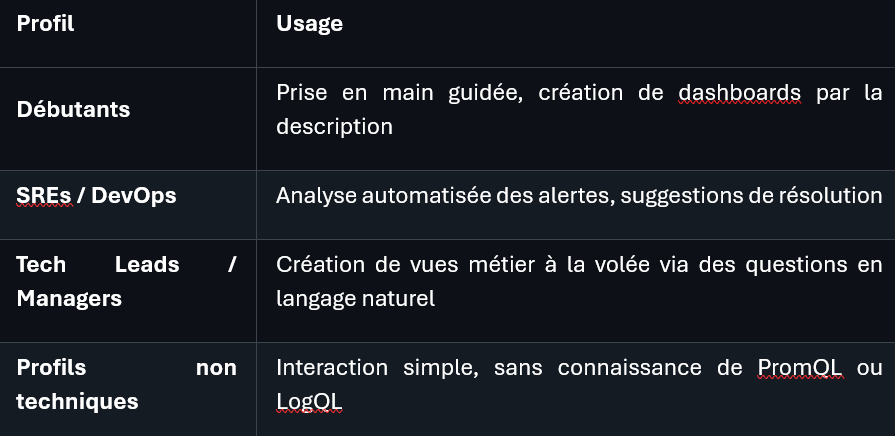
Des fonctionnalités innovantes
L'assistant ne se contente pas de répondre à des questions. Il s'enrichit de nouvelles capacités :
- Analyse des traces : en plus des métriques et des logs, l'assistant peut désormais raisonner sur les traces pour identifier des problèmes de performance distribués.
- Connexion SQL : possibilité d'interroger directement des bases de données relationnelles depuis l'assistant.
- Système de Règles : des instructions permanentes données à l'IA pour définir son comportement par exemple, "réponds toujours en français", "priorise les alertes de niveau critique", ou encore "applique toujours ces bonnes pratiques de nommage". Un vrai levier pour standardiser les pratiques à l'échelle d'une organisation.
- MCP (Model Context Protocol) : l'assistant peut se connecter à des outils externes comme GitHub ou Jira, et plus généralement à n'importe quel outil compatible MCP. Cela ouvre la voie à des workflows d'incident management entièrement intégrés.
- Infrastructure Memory : un ensemble d'agents IA qui scannent en continu l'infrastructure, enregistrent leur connaissance dans une base de données, et permettent à l'assistant de répondre de manière beaucoup plus contextualisée et précise. La connaissance est mise en cache, ce qui améliore aussi les temps de réponse.
- Intégration Slack & Teams : l'assistant peut interagir directement dans les canaux de communication de l'équipe. C'est du ChatOps natif plus besoin de basculer entre les outils pour obtenir un diagnostic.
- Playbooks : il sera possible d'enseigner à l'agent des procédures spécifiques à votre organisation. Concrètement, on peut décrire les étapes à suivre lors d'un type d'incident précis, et l'assistant les appliquera automatiquement.
- Apprentissage par l'historique : l'assistant pourra se nourrir des post-mortems et investigations passées pour améliorer ses analyses futures. Plus votre organisation l'utilise, plus il devient pertinent.
- Génération de diagrammes Mermaid : l'assistant peut produire des schémas d'architecture ou de flux directement dans l'interface.
- RBAC respecté : l'assistant opère dans les limites des droits de chaque utilisateur. Pas de risque qu'un utilisateur accède à des données auxquelles il n'est pas autorisé via l'IA.
Investigations automatisées : la fonctionnalité phare
La fonctionnalité Investigations est l'une des plus impressionnantes. Lorsqu'une dégradation de service est détectée sur un ou plusieurs services, l'utilisateur peut déclencher une investigation complète. En 5 à 10 minutes, l'agent :
- Collecte et corrèle les signaux disponibles (métriques, logs, traces)
- Formule des hypothèses et les teste
- Identifie la rootcause probable
- Produit un rapport structuré avec schéma de pensée, visualisations et actions recommandées
Ce n'est pas une boîte noire : l'assistant expose son raisonnement étape par étape, ce qui permet aux équipes de valider ou de corriger son analyse.
Grafana IRM : unifier la gestion des incidents
La gestion des incidents est souvent fragmentée entre plusieurs outils : un outil d'alerting, un outil de ticketing, un canal de communication, un outil de post-mortem… Grafana IRM (Incident Response & Management) ambitionne de tout centraliser dans une seule plateforme.
Le cycle de vie complet d'un incident
Voici comment se déroule la gestion d'un incident avec IRM :
- Détection : une alerte se déclenche, basée sur les SLO ou les règles d'alerting configurées.
- Notification : les bonnes personnes sont contactées automatiquement selon les plannings d'astreinte qui, quoi, comment est résolu sans intervention manuelle.
- Création de l’incident : depuis l'application mobile ou directement dans Grafana, un incident est créé. Un channel Slack dédié est automatiquement ouvert.
- Investigation : depuis l'incident, on peut déclencher une investigation Grafana Assistant. Les résultats remontent directement dans le canal Slack.
- Documentation : un LLM génère un rapport d'incident structuré, avec la possibilité d'utiliser des templates personnalisés.
- Vue 360° : l'équipe dispose d'une vue complète métriques et logs liés à l'incident, SLO du service concerné, durée moyenne de résolution historique, responsables du service, dépendances vers d'autres services.
- Post-mortem : le compte-rendu est produit et peut alimenter Grafana Assistant pour améliorer les futures investigations.
Intégrations et disponibilité
IRM s'intègre de manière bi-directionnelle avec les outils ITSM existants : ServiceNow, Jira, et d'autres. Les incidents peuvent être créés et mis à jour des deux côtés.
IRM n'est pas disponible en version OSS AlertManager reste l'alternative open source pour la gestion des alertes.
Une partie des fonctionnalités est accessible en Free Tier pour les 3 premiers utilisateurs.
Adaptive Telemetry : l'intelligence au service de la collecte
Adaptive Traces : ne garder que ce qui compte
Les traces sont des données extrêmement précieuses pour comprendre le comportement d'une application distribuée. Elles permettent de suivre une requête de bout en bout, à travers tous les services qu'elle traverse, et d'identifier précisément où et pourquoi une erreur ou un ralentissement se produit.
Le problème ? Les traces sont volumineuses, verbeuses et coûteuses à stocker. Dans un système à fort trafic, enregistrer 100 % des traces n'est ni viable financièrement ni nécessaire techniquement.
Adaptive Traces résout ce dilemme avec une approche intelligente :
- On attend que la trace soit complète avant de l'évaluer
- Un ensemble de critères est appliqué : la trace présente-t-elle une anomalie ? Une latence anormale ? Une erreur ?
- Si oui, elle est conservée. Sinon, elle est éliminée.
- L'IA affine en continu les critères de sélection via des règles de Predictive Telemetry
Le résultat : moins de stockage, moins de coûts, mais un signal plus propre et plus actionnable.
Profiles : plonger dans le code
Les profils (via Grafana Pyroscope) sont une dimension complémentaire souvent sous-exploitée. Là où les traces montrent où un problème se produit dans l'architecture, les profils montrent pourquoi il se produit dans le code quelle fonction consomme trop de CPU, quelle allocation mémoire est excessive, quel appel est un goulot d'étranglement.
Grafana propose désormais un échantillonnage intelligent des profils : les profils sont collectés de manière intensive uniquement lorsque des anomalies sont détectées, ce qui permet de concentrer l'analyse là où elle est vraiment utile notamment lors des releases ou des périodes de charge élevée.
OpenTelemetry sur Grafana Cloud : simplifier le déploiement
OpenTelemetry est devenu le standard de facto pour l'instrumentation des applications modernes. Il fournit un cadre unifié pour collecter métriques, logs et traces, quel que soit le langage ou la plateforme. Mais sa mise en œuvre reste complexe : de nombreux composants à assembler, des configurations spécifiques à chaque environnement, des pipelines à construire…
Comme l'a résumé un intervenant : "C'est comme avoir une énorme boîte de LEGO devant soi, sans la notice."
Grafana propose désormais une expérience simplifiée pour déployer OpenTelemetry directement depuis l'interface, en suivant une approche en couches :
1. La couche infrastructure
Grafana Alloy (le collecteur de télémétrie de Grafana) unifie la collecte de logs et de métriques en enrichissant les données avec les métadonnées d'environnement (cluster, namespace, pod, région…). Il sert de pipeline unifié pour Prometheus et Loki, simplifiant considérablement la configuration.
2. La couche services
On obtient une vision claire de la santé de chaque service et de la topologie du système comment les services communiquent entre eux, quelles sont leurs dépendances, quels sont les flux de données.
3. La couche applicative
Des bibliothèques d'instrumentation sont disponibles pour la plupart des langages courants. Le niveau de maturité varie selon les langages les protocoles REST restent par exemple plus difficiles à instrumenter que les appels gRPC.
Ce qu'il faut surveiller
- GrafanaCON Open Source se tiendra cette année à Barcelone, avec un focus sur la communauté open source et les contributions à l'écosystème.
- Grafana Tempo, le moteur de tracing distribué de Grafana, mérite une attention particulière dans les prochains mois, notamment avec les évolutions autour des Adaptive Traces.
- La question des alternatives OSS à Grafana Assistant reste ouverte aucun outil équivalent n'a été officiellement mentionné lors de l'événement.
- Pour les équipes utilisant la version Enterprise, il est possible de demander l'intégration de fonctionnalités initialement disponibles uniquement sur le Cloud, dont l'AI Assistant. Le déploiement reste simple : une licence sous forme de hash suffit, y compris dans un contexte client.
- À la suite de l’arrêt de MinIO, Grafana ne prennent pas position sur un changement de technologie. Il faudra surveiller les canaux officiels dans les prochaines semaines.
En résumé
ObservabilityCON 2026 confirme que Grafana ne se positionne plus seulement comme un outil de visualisation, mais comme une plateforme d'observabilité intelligente et intégrée. L'IA, via Grafana Assistant, est désormais au cœur du produit accessible à tous, capable de raisonner sur l'ensemble des signaux, et de plus en plus autonome dans la résolution des incidents.
Pour les organisations qui cherchent à moderniser leur approche de l'observabilité, les signaux sont clairs : l'avenir est à la télémétrie adaptative, à la corrélation automatique des signaux, et à des assistants capables non seulement de diagnostiquer, mais aussi d'agir.


