
Tomemos como ejemplo un proceso de CI/CD que permite generar una plantilla de máquina virtual de desarrollo. Este pipeline no solo permite, a largo plazo, ahorrar tiempo en la incorporación de nuevos empleados, al proporcionarles directamente una plantilla para implementar automáticamente una máquina virtual de desarrollo con todos los elementos técnicos esenciales ya configurados (redes, certificados, repositorios internos...), sino que también garantiza la coherencia y una estrategia de desarrollo sólida. De hecho, esta estrategia permite unificar el entorno de desarrollo de los desarrolladores, lo cual es una práctica fundamental para los proyectos técnicos. Para ilustrar esto, tomemos el siguiente ejemplo: un desarrollador utiliza una máquina virtual Rocky Linux 8.7, mientras que otro utiliza una máquina virtual Rocky Linux 9.2. Dado que sus entornos de desarrollo son considerablemente diferentes, es muy probable que el código funcione para el primer desarrollador pero no para el segundo, y viceversa. Por ejemplo, para instalar el paquete go, el primer desarrollador tendrá que descargar el binario de dicho paquete e instalarlo manualmente, mientras que el segundo podrá utilizar directamente los repositorios de su máquina virtual. Evidentemente, este ejemplo es simplista dadas las notables diferencias entre una máquina virtual Rocky Linux 8.7 y una 9.2, pero el problema sigue siendo el mismo en el caso de diferencias de entorno mucho más sutiles (por ejemplo, la misma versión de sistema operativo, pero con instalaciones de versiones diferentes de un paquete o de un servicio systemd entre las máquinas virtuales de los desarrolladores). Por lo tanto, la estandarización de un entorno de desarrollo dentro de un equipo de desarrollo es muy importante, y para ello la generación de pipelines de CI/CD de infraestructura como código es una ventaja considerable.
Por último, la automatización de las pruebas es otra de las ventajas que aporta un proceso de CI/CD en el mundo del desarrollo. Este aspecto permite consolidar la coherencia y la estrategia de desarrollo a largo plazo, reduciendo drásticamente los errores a la hora de integrar nuevas funcionalidades. Tomemos el siguiente ejemplo: un desarrollador implementa una nueva funcionalidad en una aplicación relativamente compleja. Una vez finalizada su tarea, comprueba que esta tiene el efecto deseado probando las diferentes partes de la aplicación que considera afectadas por sus modificaciones. Pero sin un pipeline de CI/CD, al ser la aplicación relativamente compleja, a menos que este desarrollador domine al 100 % la aplicación (lo cual es muy raro), no puede asegurarse de que sus modificaciones no afecten a partes de la aplicación que no hubiera previsto. Con el pipeline de CI/CD, esta situación no se dará, o al menos será mucho más infrecuente, independientemente del perfil del desarrollador, ya que si sus modificaciones afectan a una parte de la aplicación que no había previsto, y si las pruebas del pipeline están bien escritas, el pipeline fallará e informará directamente al desarrollador del trabajo o trabajos afectados por sus modificaciones.
Otro factor importante que explica el aumento de la demanda de estas competencias es el crecimiento exponencial del riesgo cibernético en los últimos años. Hoy en día, las empresas apuestan por la automatización para protegerse de los ciberataques (análisis estático de código, análisis dinámico de código, detección de vulnerabilidades, endurecimiento y securización del sistema operativo, etc.). Vamos a centrarnos en la creación de un proceso de CI/CD para mejorar el rendimiento del desarrollo de un proyecto que refuerza y protege una imagen ISO de una distribución de Linux (Rocky Linux 9.4).
Para este tipo de proyecto, veremos juntos qué ventajas aporta un pipeline de CI/CD. Para ello, en primer lugar crearemos un entorno de desarrollo estable y económico (mediante la creación de una nube privada utilizando servidores bare metal de OVH y nuestros propios runners de GitLab). A continuación, compilaremos automáticamente nuestra ISO centrándonos en las tareas de automatización de la compilación y la implementación propias de los pipelines de CI/CD. Después veremos juntos cómo implementar automáticamente una máquina virtual a partir de la ISO segura generada y, por último, cómo probar automáticamente dicha máquina virtual implementada, así como la seguridad de nuestro código.
Índice:
- Configuración de su nube privada
- Creación de tus propios runners de GitLab
- Tutorial rápido para crear flujos de trabajo con GitLab CI
- Creación automática de la imagen ISO
- Automatización de la detección de vulnerabilidades en el código y los contenedores
- Despliegue automático de una máquina virtual con la imagen ISO protegida
- Ejecución de pruebas automáticas mediante Ansible en tres máquinas virtuales, incluida la que se ha implementado a partir de la imagen ISO segura
- Conclusión
Configuración de su nube privada
Selección del servidor en OVH e instalación del hipervisor Proxmox V8
Para disponer de nuestra propia nube privada, vamos a utilizar un servidor bare metal de OVH e instalar en él el hipervisor Proxmox. ¿Por qué? Sencillamente porque será la solución más económica. AWS y Azure ofrecen muchos más servicios, pero son bastante más caros. Por eso, te recomiendo que elijas un servidor bare metal del tipo «So you start» de OVH. Hay un total de 29 con recursos más o menos similares y a 27,50 euros al mes sin compromiso. Puede parecer caro a primera vista, pero no lo es, ya que tendrás libertad para utilizar tu servidor como mejor te parezca y, por lo tanto, no pagarás por uso, lo cual es mucho más caro. Por mi parte, he elegido el servidor SYS-1-SSD-32, que ofrece 32 GB de RAM, 8 CPU y 2 discos SSD de 480 GB de almacenamiento por 27,50 euros al mes sin compromiso. Para ello, crea una cuenta en OVHcloud, ve a Bare Metal Cloud --> Pedir --> Servidor dedicado y, a continuación, selecciona en la parte inferior de la página los servidores «Eco» (ver captura de pantalla 1) y el servidor «So you start» que prefieras (ver captura de pantalla 2).

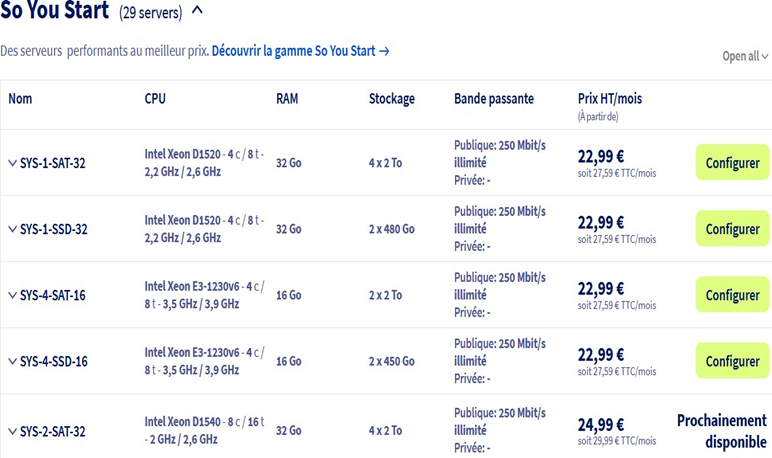
Una vez realizado el pedido, OVH te ofrece plantillas de instalación para numerosas distribuciones (Alma Linux, Ubuntu, Windows, Rocky Linux... Proxmox). Vamos a utilizar la plantilla de Proxmox 8 para instalar el hipervisor Proxmox 8 en nuestro servidor.

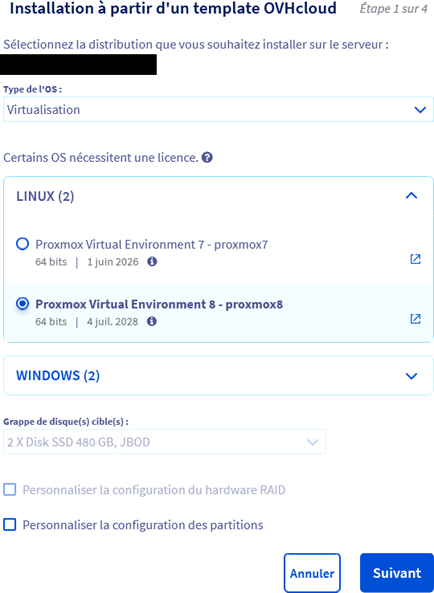
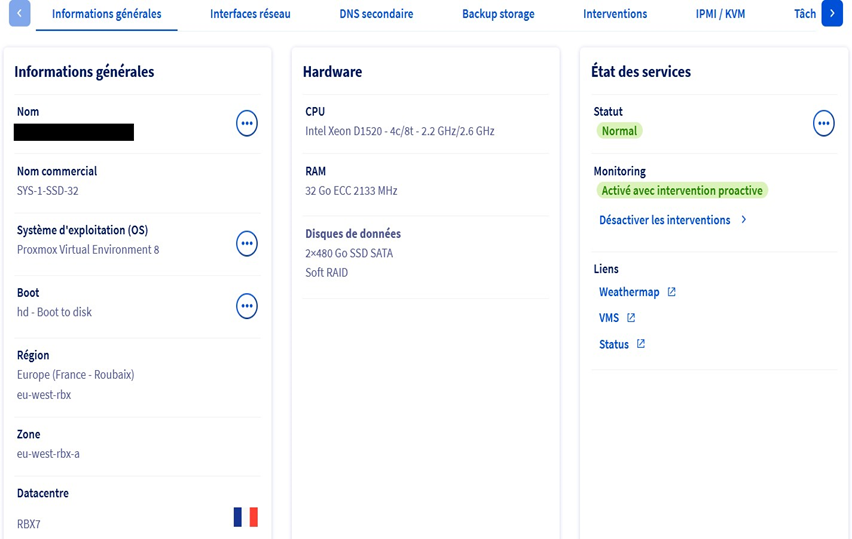
Se puede ver que mi servidor OVH tiene como sistema operativo Proxmox V8, que cuenta con 32 GB de RAM, 8 núcleos de CPU y 2 discos SSD de 480 GB, y que está alojado en el centro de datos de OVH en Roubaix.
Configuración de seguridad:
Así pues, ya tenemos nuestro hipervisor Proxmox alojado en nuestro servidor, por lo que podemos empezar a configurarlo. Empecemos por algunas configuraciones de seguridad:
- Cambio de los puertos predeterminados de los servicios habituales (por ejemplo, para los servicios http, https y ssh: sustitución de los puertos 80 por 8080, 443 por 4433 y 22 por 2222). IMPORTANTE: asegúrate de informar a SELinux de los cambios de puertos; de lo contrario, SELinux bloqueará el acceso. Para ello, ejecute como administrador el comando semanage port -a -t service_port_t -p tcp
- new_port_number (por ejemplo, semanage port -a -t ssh_port_t -p tcp 2222 para informar a SELinux del cambio de puerto para el servicio SSH)
- Creación de un usuario «admin» para no tener que utilizar la cuenta «root». Protección de las conexiones SSH:
- Desactivar el inicio de sesión con la cuenta de root
- Desactivar el inicio de sesión con contraseña (solo se podrá iniciar sesión mediante clave SSH)
- Configurar el número máximo de intentos para autenticarse (5)
Para realizar estas acciones, conéctese por SSH con el usuario «admin» que ha creado y, a continuación, modifique el archivo de configuración /etc/ssh/sshd_config con los datos que aparecen en la siguiente captura de pantalla:
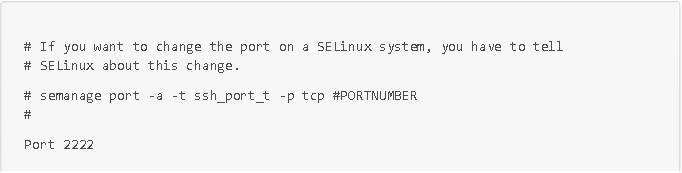
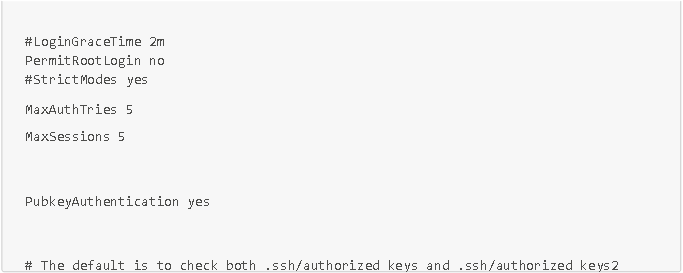
Estas pequeñas configuraciones de seguridad rápidas son muy eficaces para contrarrestar los ataques de bots.
Configuración de red
Ahora que hemos protegido un poco nuestro servidor contra los ataques de bots, podemos configurar la red. Si bien el equipo de OVH ya ha configurado la red de nuestro servidor, lamentablemente no será así en el caso de las máquinas virtuales que vamos a crear en nuestro hipervisor Proxmox (alojado en nuestro servidor). Para ello, vamos a adquirir una IP adicional (también en OVH) y, a continuación, crear una máquina virtual de enrutamiento que enrutará la red de la máscara de subred de esta IP adicional a todas las máquinas virtuales que vamos a crear en nuestro hipervisor Proxmox. Utilizaremos una máquina virtual Opnsense como máquina virtual de enrutamiento, pero también puedes utilizar una máquina virtual PfSense si lo prefieres.
Para solicitar una IP adicional en OVH: ve a Bare Metal Cloud --> Pedir --> IP
adicional --> IPv4 --> IP adicional. A continuación, puedes descargar la imagen ISO de una máquina virtual Opnsense en la siguiente dirección: https://opnsense.org/download/.
Antes de crear nuestra máquina virtual de enrutamiento, debemos crear un nuevo puente de red en nuestro hipervisor Proxmox, para disponer de una interfaz LAN y una WAN para nuestra máquina virtual de enrutamiento. Para ello, ve a proxmox-1 --> red y añade el puente vmbr1 asignándole la red Ethernet disponible eno4 (véase la captura de pantalla a continuación).
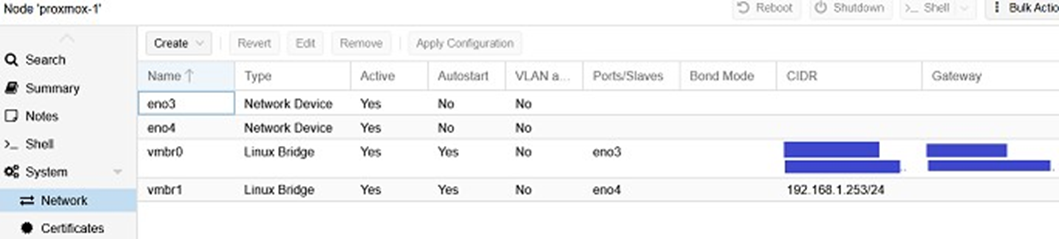
Una vez creado este puente de red, podemos crear nuestra máquina virtual Opnsense. Para ello, crea una máquina virtual en Proxmox utilizando la imagen ISO de Opnsense descargada anteriormente y las siguientes configuraciones:
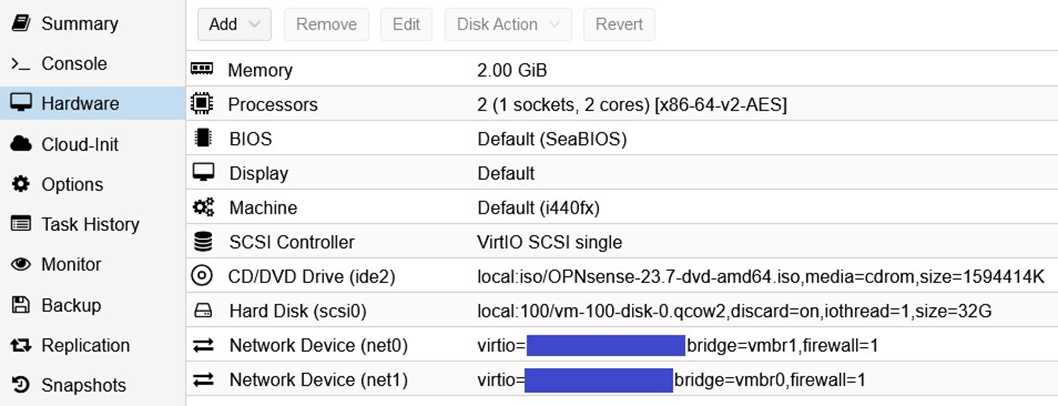
IMPORTANTE: en cuanto a las configuraciones de red, fíjate en que he ocultado las direcciones MAC. La dirección MAC del puente vmbr1 se completa automáticamente y sin problemas (net0); sin embargo, en el caso del puente vmbr0 (net1), es muy importante que introduzcas manualmente la dirección MAC de tu IP adicional. Para ello, solo tiene que consultar en OVH Cloud las características de su dirección IP adicional.
Ahora que tenemos nuestros dos dispositivos de red correctamente configurados mediante nuestros dos puentes (vmbr0 y vmbr1) y nuestra IP adicional, podemos iniciar la máquina virtual Opnsense. La máquina virtual comenzará entonces su instalación y configuración para enrutar la red, configurando una LAN (red de área local) en el dispositivo de red net0 utilizando el puente vmbr1 y una WAN (red de área amplia) en el dispositivo de red net1 utilizando el puente vmbr0. Finalizará la configuración de la LAN, pero no la de la WAN, ya que necesitará la dirección IP adicional. Por lo tanto, debe configurar la WAN manualmente. Para ello, debe autenticarse en la VM con las credenciales predeterminadas, que son: nombre de usuario: root y contraseña: opnsense; a continuación, cambie la contraseña por motivos de seguridad con la opción 3 y asigne su dirección IP adicional a la interfaz WAN utilizando la opción 2. Si todo va bien, debería ver su dirección IP adicional definida en la WAN, y la red debería estar activada en todas las máquinas virtuales de su nodo Proxmox que tengan como interfaz de red el puente vmbr1.
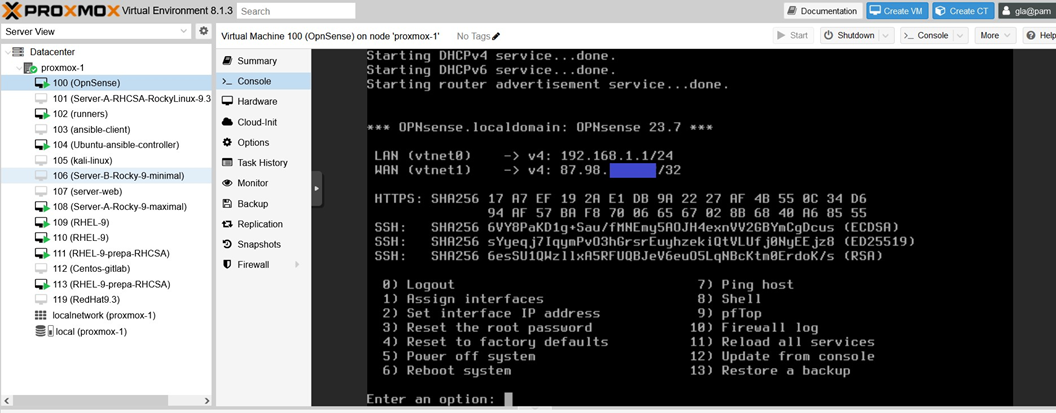
Ahora que nuestro hipervisor Proxmox está listo y bien configurado en nuestro servidor bare metal, disponemos de un entorno de pruebas estable en el que podemos realizar las pruebas que queramos y empezar a crear pipelines de CI/CD. Sin embargo, antes de crearlos, tendremos que crear nuestros propios runners.
Creación de tus propios runners de GitLab:
Para ejecutar procesos de automatización de CI/CD, GitLab utiliza «runners» que proporciona directamente, pero estos «runners» tienen limitaciones de uso, que varían según la versión de GitLab (solo 200 minutos de CI/CD y, sobre todo, 5 GB de almacenamiento en la versión gratuita, 10 000 minutos al mes para la versión premium, pero a 29 euros al mes, lo que para esta última versión es más que suficiente para un particular, pero resulta bastante caro y a menudo insuficiente para las grandes empresas). Puede consultar los detalles de las tarifas de las tres fórmulas de GitLab en la siguiente dirección: https://about.gitlab.com/fr-fr/pricing/. Para no tener limitaciones en la ejecución de nuestros pipelines, vamos a crear nuestros propios runners de GitLab en nuestra nube privada. Existen numerosos runners de GitLab, pero solo crearemos los dos tipos más utilizados: los runners de shell y los runners de Docker. Esto será más que suficiente para nuestro proyecto.
Para obtener más detalles sobre todos los tipos de runners disponibles, puede consultar la página https://docs.gitlab.com/runner/executors/.
Para disponer de nuestros propios runners de GitLab, los crearemos en una máquina virtual Linux de nuestro servidor con gran capacidad de almacenamiento (200 GB de almacenamiento, máquina virtual 102 Runners de mi hipervisor Proxmox con la distribución Rocky 9.2, como se muestra en la captura de pantalla anterior). Una vez que tengamos una máquina virtual con gran capacidad de almacenamiento, debemos crear el runner manualmente en nuestro proyecto de GitLab. Para ello, cree un proyecto en GitLab y vaya a Settings --> CI/CD --> Runners --> New Project runner de su proyecto. A continuación, añada etiquetas que le resulten significativas (estas etiquetas se utilizarán para llamar a sus runners en los trabajos de su pipeline). Por ejemplo, puede definir como etiqueta: proxmox o my-first-runner. A continuación, pulse Create runners y su runner se creará por defecto para una plataforma Linux y se mostrará su token de autenticación (copie este último cuidadosamente).
Ya tenemos nuestro runner creado, pero aún no está vinculado a la máquina virtual de nuestro servidor en la que queremos alojarlo. Para ello, tenemos dos métodos posibles: utilizar el comando gitlab-runner en un sistema operativo Linux, o utilizar la imagen Docker gitlab/gitlab-runner (dado que mi máquina virtual de almacenamiento es una Rocky 9.2, ambos métodos son viables para esta máquina virtual). A continuación se describen estos dos métodos:
A través de Linux
A través de Docker (IMPORTANTE: asegúrate de utilizar el servicio Docker y no Podman)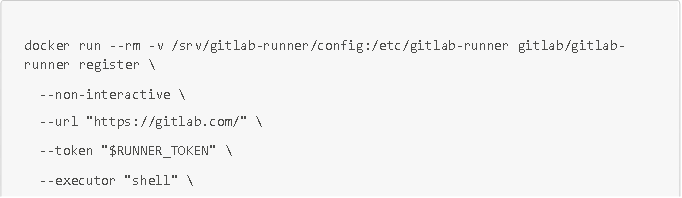
Con $RUNNER_TOKEN, el token de autenticación del runner.
NOTA: para crear un runner de Docker, solo tienes que utilizar los mismos comandos, pero con el argumento «docker» para el parámetro «--executor».
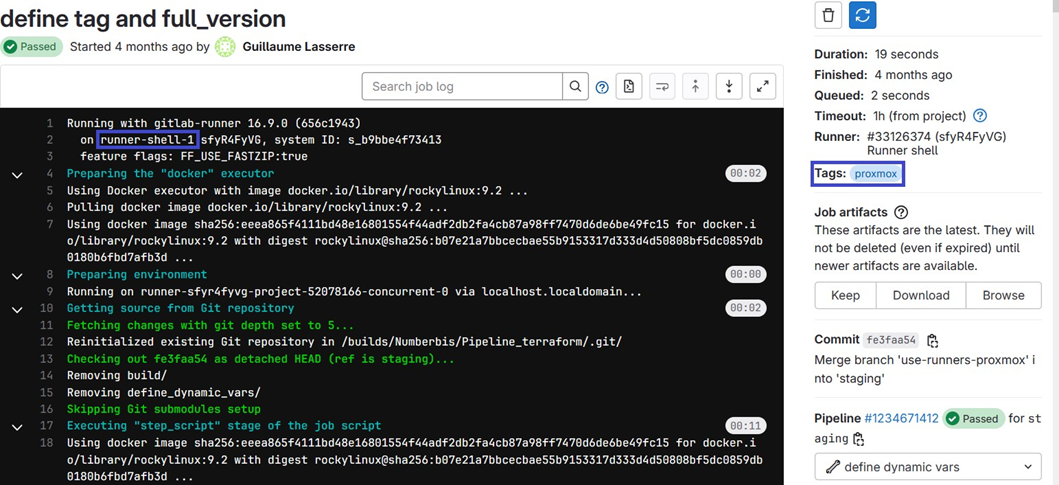
EJEMPLO: a continuación se muestra la ejecución de un trabajo de canalizaciones de CI/CD realizada desde nuestro propio ejecutor «runner-shell-1» y llamada por el trabajo mediante la etiqueta «proxmox» (véanse los recuadros azules).
Tutorial rápido para crear flujos de trabajo con GitLab CI
Para crear un pipeline en uno de tus proyectos de GitLab, debes crear un archivo de configuración YAML llamado .gitlab-ci.yml en el directorio raíz de tu proyecto. Este archivo te permitirá configurar tu pipeline. A continuación te ofrecemos algunos consejos para configurarlo.
Orden de las prácticas y ejecución de los trabajos
Para definir el orden de ejecución de las etapas, puedes especificarlo al principio del pipeline, después de la línea «stages»: si incluyes varios trabajos en la misma etapa, se ejecutarán en paralelo (es decir, al mismo tiempo), siempre y cuando dispongas de suficientes ejecutores disponibles para todos los trabajos. Para mayor claridad y visibilidad en la ejecución de trabajos en paralelo (por ejemplo, cuando hay más de una decena de trabajos que se deben ejecutar en paralelo), se recomienda utilizar una matriz mediante el comando matrix.
Variables de entorno
Para definir variables de entorno, puedes utilizar la instrucción «variables»: Además, GitLab pone a tu disposición numerosas variables predefinidas muy útiles, como por ejemplo la variable.
CI_COMMIT_BRANCH, que indica el nombre de la rama, o la variable CI_COMMIT_SHA, que indica el hash de la confirmación. Puedes encontrar todas estas variables en la siguiente dirección: https://docs.gitlab.com/ee/ci/variables/predefined_variables.html.
Entorno de ejecución de un trabajo y legibilidad del código
Los trabajos se ejecutan en contenedores cuyas imágenes deben definirse en el parámetro «image» del trabajo. Los runners que ejecutan los trabajos se eligen a partir de la variable tags (ver captura de pantalla). Si no se define esta variable, el pipeline se ejecuta por defecto con runners compartidos de GitLab. Para mejorar la legibilidad de tu código y de tu pipeline, puedes utilizar emojis del proyecto Gitmoji. Esto resulta muy útil, sobre todo para diferenciar claramente las etapas.
Creación automática de la imagen ISO
Ahora que ya hemos creado y configurado nuestra infraestructura de pruebas (nube privada y runners de GitLab), podemos empezar a automatizar la compilación de nuestra imagen ISO segura. Para ello, seguiremos estos tres pasos:
- Definición de una estrategia de nomenclatura de los artefactos y puesta en marcha del proceso
- Descarga de la imagen ISO de Rocky Linux 9.4 y modificación automática de la misma para garantizar su seguridad
- Implementación automática de la imagen ISO segura en un repositorio
Definición de una estrategia de nomenclatura de los artefactos y puesta en marcha del proceso
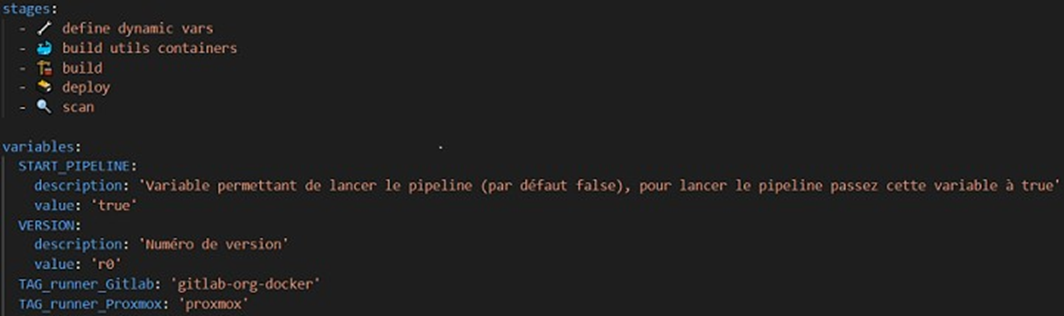
En cualquier pipeline de CI/CD, el primer paso es configurar un método que permita definir de forma eficaz y automática una nomenclatura para los artefactos, con el fin de garantizar que los resultados de una ejecución no se sobrescriban con los de otra. Por ejemplo, sin una configuración automática de la nomenclatura de los artefactos, los artefactos de cada ejecución tendrían el mismo nombre y, por lo tanto, los resultados de la ejecución N-1 serían sobrescritos por los resultados de la ejecución N. Otro elemento a tener en cuenta: la frecuencia de ejecución del pipeline; de hecho, si bien en las ramas de producción (main o master) o de desarrollo común (qa, develop o staging) es importante ejecutar el pipeline automáticamente para cada commit, no es así en el caso de las ramas de desarrollo de los desarrolladores, que solo lanzan el pipeline cuando creen haber terminado sus desarrollos, y no con cada commit. Por lo tanto, es importante configurar estos dos elementos de forma automática en nuestro pipeline. Para ello, utilizaremos un trabajo que definirá automáticamente, mediante un script bash, las variables de entorno según la rama de ejecución del pipeline y, a continuación, añadiremos una regla a nuestro archivo de configuración para definir cuándo debe iniciarse el pipeline.
Regla que permite o no el inicio de un proceso

Esta regla, añadida al archivo .gitlab-ci.yml, permite iniciar el pipeline si un desarrollador que desea probar su código ha establecido la variable START_PIPELINE, disponible en la interfaz de GitLab, en True, o si la rama es una rama de producción o de desarrollo común (master, main o develop).
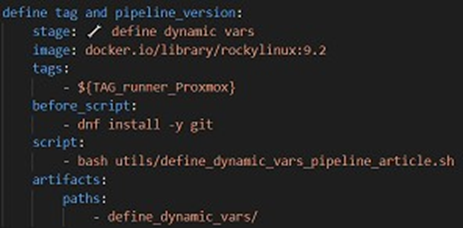
A continuación, se muestra el trabajo en el archivo de configuración .gitlab-ci.yml, así como el script de Bash. Observará que este script permite definir las variables de entorno TAG y PIPELINE_VERSION. La variable PIPELINE_VERSION permitirá tener un nombre único de artefacto para cada ejecución del pipeline y, de este modo, evitar conflictos de artefactos durante su implementación en los repositorios. Nota: la variable $VERSION del script tiene un valor predeterminado de V1_dev y está configurada de manera que los desarrolladores puedan introducir este valor directamente en la interfaz de GitLab (si desean tener un nombre de artefacto más descriptivo que el nombre de su rama seguido de r1_dev o, sobre todo, si quieren ejecutar el pipeline varias veces en una misma rama de desarrollo).
Script de Bash que define automáticamente la nomenclatura de los artefactos
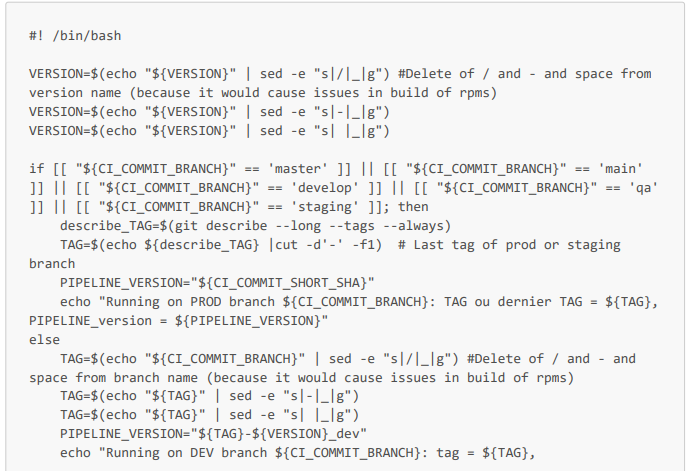
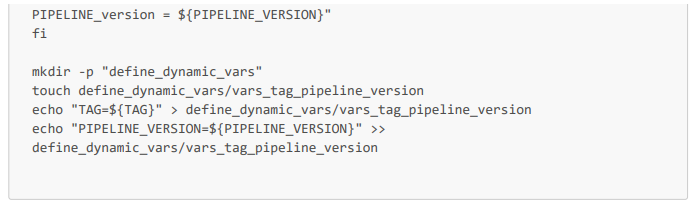
Tarea del pipeline en el archivo de configuración .gitlab-ci.yml

On peut noter que ce job s'applique dans un conteneur rockylinux 9.2 (créé à partir de l'image docker.io/library/rockylinux:9.2), qu'il est exécuté par un de nos runners (de tag ${TAG_runner_Proxmox}), donc directement dans notre serveur, et qu'il enregistre en artifacts le dossier define_dynamic_vars.
Descarga de la imagen ISO mínima de Rocky Linux 9.4 y modificación de la misma para mejorarla en materia de seguridad y añadirle nuevas funciones
Para descargar una imagen ISO de Rocky Linux 9.4 y modificarla automáticamente con el fin de protegerla mediante una tarea de la canalización de CI/CD, primero crearemos, en un contenedor de Rocky Linux 9.3, un script de Bash que nos permita realizar todas las tareas necesarias. Una vez que hayamos probado este script, lo ejecutaremos directamente en una canalización de CI/CD (siempre a través de GitLab-CI y con nuestros runners).
Empecemos, pues, a escribir nuestro script. El primer paso es instalar los paquetes necesarios. En nuestro caso, tenemos que instalar tres paquetes: wget para descargar la imagen ISO, genisoimage (equivalente a xorrizo) para modificarla y sudo para gestionar los permisos. Una vez instalados los paquetes necesarios, descargamos la imagen ISO con wget. A continuación, podemos empezar a modificar nuestra imagen ISO. Para ello, primero debemos montar la imagen ISO en nuestro sistema en uno de nuestros directorios vacíos (por ejemplo, /mnt/iso) y, a continuación, copiar todas las carpetas y archivos de configuración de la imagen ISO montada a nuestro directorio de trabajo temporal (variable $WORKDIR del script).
De este modo, tenemos todos los archivos y los archivos de configuración de nuestra ISO guardados en nuestro directorio de trabajo (WORKDIR), y podemos aplicarles todos los cambios que queramos para añadirles funcionalidades (por ejemplo, añadiendo paquetes RPM), reforzar sus configuraciones y protegerla.
Por motivos de confidencialidad, no realizaremos cambios muy avanzados en la configuración de seguridad ni crearemos paquetes RPM seguros, pero este será un primer paso para comprender el enfoque que hay que adoptar a la hora de modificar y proteger una imagen ISO. Por ejemplo, podemos aplicar las reglas de seguridad que implementamos en nuestro servidor en la primera parte (cambio de los puertos predeterminados para los servicios SSH, HTTP y HTTPS, y protección de las conexiones SSH) y añadir una entrada de montaje. Para ello, solo tenemos que asignar las nuevas configuraciones de seguridad a las configuraciones existentes de la ISO y, para nuestro montaje, añadir una entrada en el archivo /etc/fstab.
Lo que nos da el siguiente script (al que llamaremos download_and_modify_iso_rocky_9_4.sh en la tarea de nuestro pipeline).
Script completo de Bash:

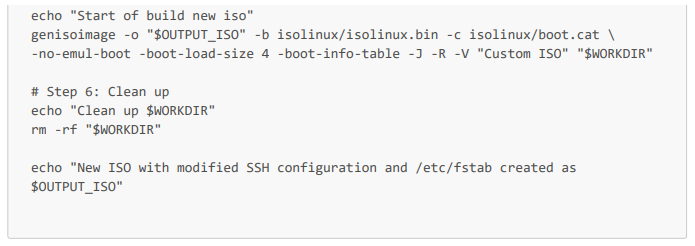
Para automatizar esto en nuestro proceso de CI/CD, solo tenemos que ejecutar este script (download_and_modify_iso_rocky_9_4.sh) en un contenedor de Rocky Linux 9.3 o en cualquier otro contenedor compatible. Por ejemplo, también podríamos utilizar un contenedor de Red Hat. A continuación se muestra una tarea que ejecuta este script en un proceso de GitLab CI:

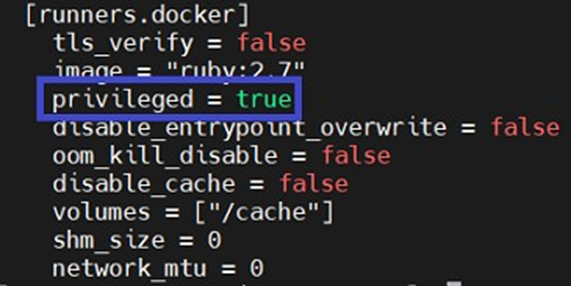
IMPORTANTE: ten en cuenta que, para montar archivos ISO, los contenedores necesitan permisos adicionales (mediante la opción --privileged), por lo que deberás asegurarte de modificar la configuración de tu runner (archivo /etc/gitlab-runner/config.toml) estableciendo el parámetro privileged de tu runner en true (véase la captura de pantalla a continuación). De lo contrario, al ejecutar el pipeline, el script se bloqueará en tu contenedor Rocky Linux 9.3 al montar la ISO.
Implementación de la imagen ISO segura en un repositorio
Lo ideal es que las grandes empresas den prioridad a soluciones de almacenamiento como Artifactory, Azure Datalake o Amazon S3. Sin embargo, dado que nuestros recursos son demasiado limitados (32 GB de RAM y 2 discos SSD de 480 GB de almacenamiento) para montar una instancia de Artifactory, y teniendo en cuenta que Azure Datalake y Amazon S3 son caros, simplemente almacenaremos nuestros artefactos en una carpeta llamada «repos_artifacts» de una máquina virtual creada en nuestra instancia de Proxmox.
NOTA: si tu empresa utiliza Artifactory, te recomiendo que utilices la biblioteca requests de Python para implementar automáticamente tus artefactos.
De este modo, contamos con una compilación automática, lo que no solo permite acelerar el proceso de compilación de los desarrolladores de ciberseguridad, sino también, y sobre todo, proporcionarles un entorno de desarrollo perfectamente estandarizado para el proyecto, lo que mejora drásticamente su eficiencia en proyectos de alta complejidad técnica. Insisto en este punto porque, con mucha frecuencia, los responsables de gestión de proyectos y los directivos lo subestiman. Para detallar y comprender mejor esta ventaja, la compilación automática permite garantizar que los desarrollos de un desarrollador puedan integrarse correctamente en la aplicación sin crear problemas funcionales importantes, y asegurar que cada desarrollador pruebe sus cambios exactamente en la misma infraestructura (con versiones y configuraciones idénticas en todos los aspectos), lo que permite identificar más rápidamente los conflictos entre los cambios de los desarrolladores.
Ahora que la automatización de la compilación ha concluido y los desarrolladores pueden utilizarla para ganar en eficiencia, el siguiente paso de gran valor añadido en el proceso de desarrollo es la automatización de las pruebas. En el contexto actual, caracterizado por un elevado riesgo cibernético, es importante automatizar, en primer lugar, las comprobaciones de vulnerabilidades del código y de los contenedores.
Automatización de la detección de vulnerabilidades en el código y los contenedores
Para automatizar las comprobaciones de vulnerabilidades a nivel de contenedores, la imagen Docker de Trivy resulta muy útil.
Para utilizarla directamente en un pipeline de GitLab CI, puedes emplear el siguiente trabajo sustituyendo la variable IMAGE_NAME_TO_SCAN por la imagen Docker que desees analizar mediante Trivy. Trivy generará entonces un informe de seguridad en forma de artefacto (denominado trivy_report.txt para nuestro trabajo).

Además, para automatizar las comprobaciones de vulnerabilidades en el código mediante análisis estáticos y dinámicos, puedes utilizar Checkmarx o Sonarqube.
Ahora que hemos comprobado la seguridad de nuestras imágenes de Docker mediante Trivy, podemos comenzar con las pruebas funcionales. Para ello, el primer paso es automatizar en nuestro pipeline la creación y el despliegue de una máquina virtual con la imagen ISO segura. Posteriormente, automatizaremos las pruebas en esa máquina virtual.
Creación y despliegue automático de una máquina virtual con la imagen ISO protegida
Para ello, se pueden utilizar varios lenguajes de IAC (infraestructura como código), como Terraform, Packer o Ansible, entre otros. Por nuestra parte, vamos a utilizar el comando qm que proporciona la API de Proxmox. Este comando nos permitirá crear (o eliminar) automáticamente máquinas virtuales en Proxmox a partir de scripts. Por ejemplo, el siguiente script permite crear e iniciar directamente en Proxmox una máquina virtual basada en la imagen ISO segura que hemos creado anteriormente y que se llama Rocky9.4_securise_demo:
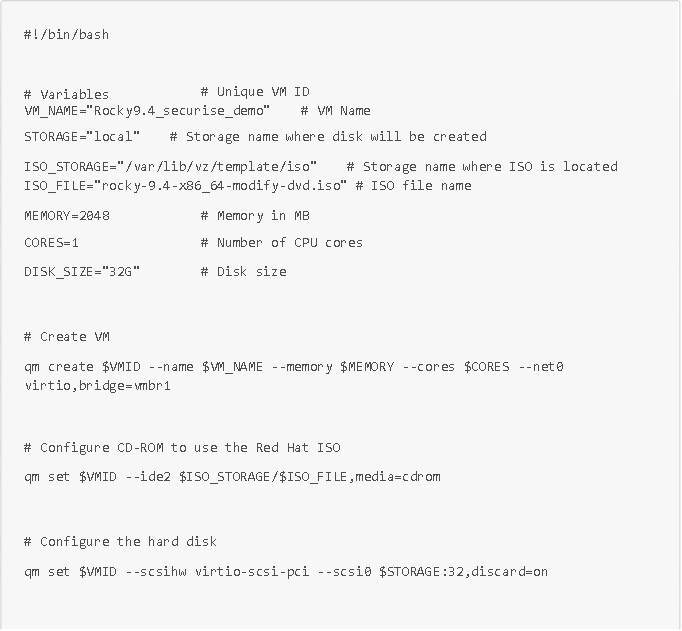

Ahora que nuestra máquina virtual, con nuestra imagen ISO reforzada y segura, ya está creada e implementada en nuestro hipervisor Proxmox, podemos automatizar las pruebas en esta máquina virtual mediante Ansible.
Aplicación de pruebas automáticas en varias máquinas virtuales mediante Ansible
Ahora vamos a pasar a la parte de automatización de pruebas. Para ello, en el ámbito de la infraestructura como código, Ansible es una herramienta muy potente por su facilidad de uso, su flexibilidad y su idempotencia (la propiedad de no ejecutar una tarea si ya se ha realizado). Con este lenguaje, podemos llevar a cabo una gran variedad de pruebas de infraestructura. Por ejemplo, podemos verificar automáticamente el estado del sistema y sus recursos disponibles, su seguridad (mediante la comprobación del estado de SeLinux para máquinas virtuales Linux, por ejemplo), su configuración de red, sus copias de seguridad, sus registros...
Por nuestra parte, veremos cómo automatizar las comprobaciones del estado de salud, los recursos disponibles y la seguridad de tres máquinas virtuales, incluida la nuestra, creada a partir de la imagen ISO reforzada y modificada. Más concretamente, en cuanto al estado de salud y los recursos disponibles, comprobaremos el almacenamiento y la memoria disponibles, los promedios de CPU y el funcionamiento de los servicios críticos (en particular, httpd y sshd). En cuanto a la seguridad, comprobaremos que los paquetes estén actualizados, las reglas del cortafuegos, el estado de SELinux, la ausencia de usuarios no autorizados y que la política de contraseñas de las máquinas virtuales cumpla con los estándares de seguridad.
Aquí tienes un playbook de Ansible (que llamaremos system_health_and_security_tests.yml) que permite realizar estas pruebas:

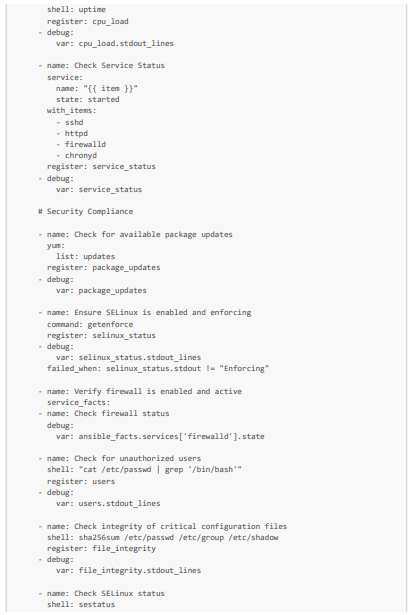
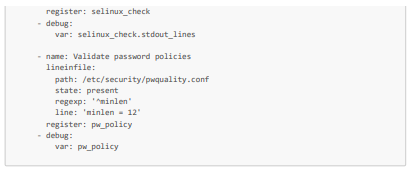
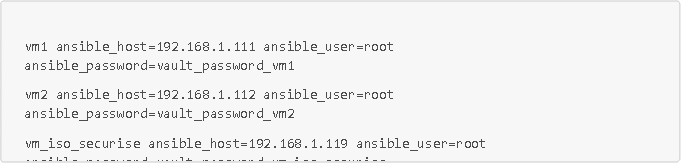
Aquí tienes también el inventario de nuestro playbook con nuestras tres máquinas virtuales (al que llamaremos inventory.ini)
Para ejecutar este playbook:

Conclusión
Así, la integración de los pipelines de CI/CD con la infraestructura como código (IAC) aporta importantes ventajas al desarrollo de software y a las operaciones. De hecho, al automatizar el proceso de implementación (es decir, la compilación estandarizada y la verificación de las pruebas), los pipelines de CI/CD garantizan que los cambios en la infraestructura sean coherentes, reproducibles y menos propensos a errores humanos. Esto permite mejorar la fiabilidad y la estabilidad de los entornos, así como reducir los errores y los riesgos asociados a las configuraciones manuales.
Además, el uso de pipelines de CI/CD facilita una implementación más rápida de los cambios en la infraestructura, lo que permite a los equipos responder con agilidad a las necesidades cambiantes de la empresa. Las pruebas automatizadas dentro de los procesos garantizan que todos los cambios se validen antes de llegar a producción, lo que permite mantener altos estándares de calidad y seguridad. El control de versiones, fundamental en la infraestructura como código, combinado con la CI/CD, fomenta la transparencia y la responsabilidad, lo que facilita el seguimiento de los cambios y la reversión de los mismos si es necesario.
No obstante, aunque los flujos de trabajo de CI/CD son imprescindibles y muy eficaces para impulsar la productividad de los desarrolladores mediante entornos de desarrollo estandarizados y pruebas automatizadas, así como para automatizar la supervisión de los sistemas, suelen estar estrechamente vinculados a entornos específicos o a herramientas concretas, lo que puede reducir su portabilidad. Por ejemplo, un pipeline diseñado para funcionar en un entorno de nube concreto (como AWS, Azure o, en este caso, Proxmox) podría requerir ajustes para funcionar en otros lugares. Además, a menudo resulta difícil gestionar toda la infraestructura informática subyacente desde un pipeline de CI/CD, como por ejemplo la gestión de la red o del almacenamiento. Para paliar estas dos dificultades, el uso combinado de nuestros pipelines de CI/CD con Kubernetes es un enfoque muy adecuado, ya que Kubernetes está diseñado para ser multiplataforma y poco dependiente de los proveedores de nube, lo que aumenta la portabilidad, y puede gestionar todas las configuraciones de la infraestructura subyacente (como las configuraciones de red y almacenamiento, por ejemplo).
En general, la combinación de los procesos de CI/CD y la infraestructura como código permite a las organizaciones ganar en eficiencia, rapidez y confianza en la gestión de su infraestructura, lo que da lugar a entornos informáticos más sólidos y escalables que fomentan la innovación continua. Y esta combinación puede mejorarse y reforzarse aún más con Kubernetes.



