By Rick H. - Cybersecurity Expert at Squad
Nowadays, huge amounts of diverse information are generated, some of which is sensitive and must be protected. With the arrival of new compliance requirements such as the military programming bill, the GDPR, and PCI-DSS, companies must comply. To do so, lengthy projects must be implemented and sometimes all or part of the existing architecture must be reviewed.
Fortunately, there are solutions available to protect this sensitive data while complying with or avoiding these regulations. Typically, PCI-DSSmainly concerns the handling of card number data, so if we arrange to no longer handle card numbers themselves but "something else," we are no longer within the scope of PCI-DSS.
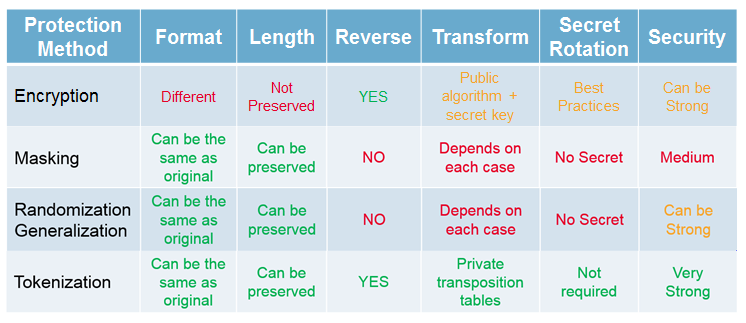
We will briefly present four types of data protection: encryption, masking, anonymization, and tokenization.
Encryption
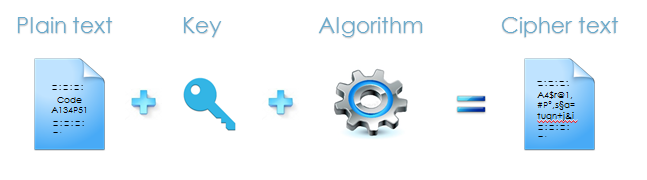
Encryption is the best-known method of protection. It involves using a widely known algorithm, known as an encryption algorithm, combined with a key, known as a secret key. The aim is to take a text known as "plain text" as input and produce a string of incomprehensible characters known as "cipher text." Unlike hashing, this operation is reversible. However, it does not preserve the original length or format.
Masking
Masking consists, as its name suggests, of masking certain characters in order to prevent the source from being traced. This is the method used on your credit card receipts, where generally only the last four characters are visible. The problem, as you may have guessed, is that by correlating the same initial data that has been masked several times in different ways, we may be able to trace it back to its source.

Anonymization
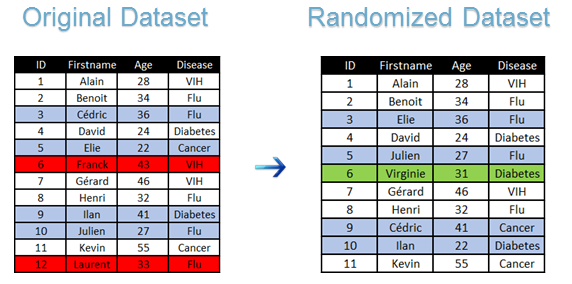
Anonymization is a fairly broad method that could be discussed at length, but I will simply explain the basics. It can be broken down into two main categories: randomization and generalization. The main purpose of both methods is to "blur" information. Randomization alters an initial dataset (typically a list of a company's employees and their salaries) using methods such as adding noise, permuting, or deleting data. An example of a randomized dataset:
Generalization
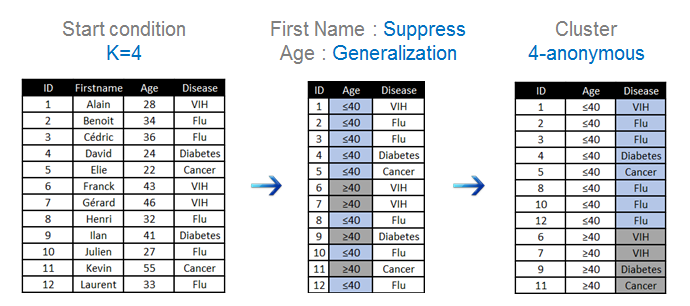
Generalization, on the other hand, does not alter the initial dataset but simply makes it sufficiently vague so that there is only a 1 in X chance (where X is to be defined) of tracing it back to the source. The main methods used are k-anonymity and l-diversity, but I won't go into detail about them here. Here is a simple example of how they are applied:
Tokenization
Tokenization is a relatively recent and innovative technique. It involves transforming sensitive data into a "token" with no intrinsic value. It is reversible and also preserves the original length and format. It is based on a method of transposing dynamic tables so that secret keys and their rotations do not have to be managed, which also increases the security of the algorithm because it is unknown to a potential attacker, unlike in the case of encryption, where an attacker would "only" have to find the key. The most classic example of tokenization is still that of credit card numbers, where the output is another credit card number of the same length but with no intrinsic value. It is also possible to protect only part of the data, in the case of birth dates or emails, for example. Furthermore, we may decide that we are not interested in the format of the initial data and simply want to make it unreadable by replacing the characters with others. Here are some classic examples:
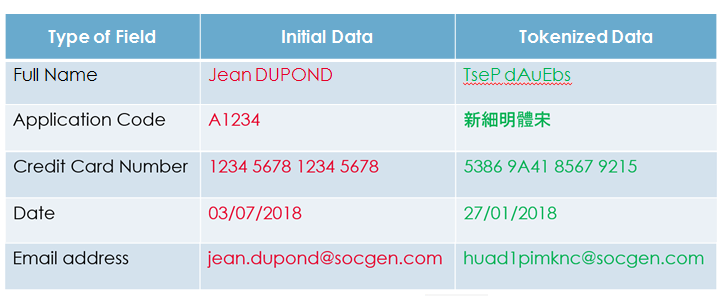
Finally, to better capitalize on all this information, here is a small comparative table between the methods we have just mentioned: