
Sonatype's 2024 edition ofAll Days DevOps (ADDO)brought together experts from around the world to discuss critical issues in software security, infrastructure, and cloud-native development.
Beyond the individual presentations, cross-cutting themes emerged, revealing trends and challenges common to all levels of engineering and software innovation. This RETEX brings these topics together to provide a coherent overview of the issues and solutions presented at the event.
Open Source Supply Chain Security: A Silent Threat

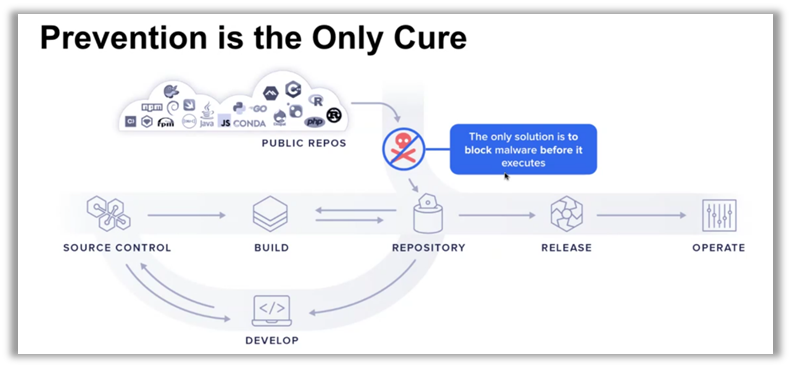
Open source components, ubiquitous in modern software supply chains, have become a major attack vector for cybercriminals. Ilkka Turunen, Field CTO at Sonatype, highlighted the rise of malware hidden within these components. These attacks integrate directly into information systems, often without being detected by traditional security measures. It is crucial to understand that reactive solutions are no longer sufficient; proactive prevention is now an urgent necessity.
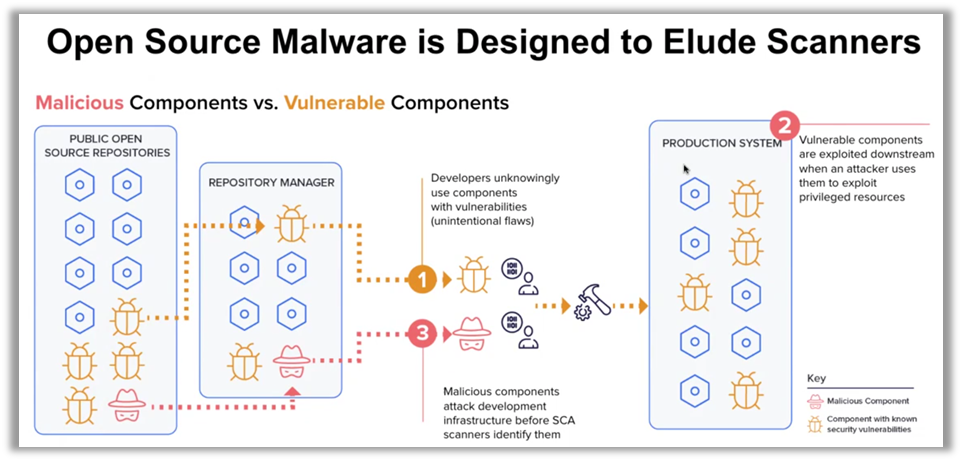
The numbers speak for themselves: approximately 50% of unprotected open source repositories contain malicious packages. This reveals a fundamental vulnerability in the way companies manage their supply chains. To overcome this threat, organizations must rethink their approach, incorporating continuous vigilance and prevention strategies well upstream of development cycles.
"Software supply chain security isn't just about fixing vulnerabilities, it's about preventing attacks before they even happen."🚨 - Ilkka Turunen
Modernizing infrastructure with microinfrastructure
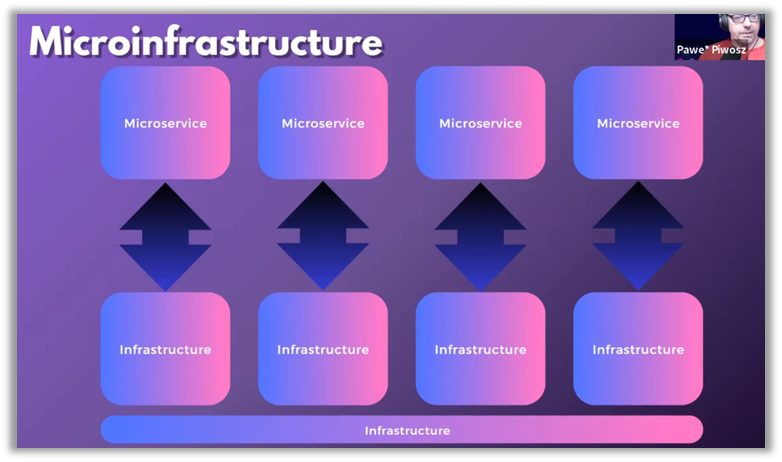
The shift towards microservices architecture has been an important step towards decentralizing software development and making it more agile. However, the underlying infrastructure has often failed to keep pace with this evolution. Pawel Piwosz from Tameshi proposes the concept of microinfrastructure to align infrastructure with the modularity of microservices, making each service more autonomous, flexible, and resilient.
This involves a profound transformation where each department benefits from a dedicated infrastructure, designed specifically to meet its unique needs. By enabling amodular infrastructure, this approach not only enhances resilience but also overall operational efficiency.

This microinfrastructure model also aims to improve organizational agility by enabling development teams to deploy and modify infrastructure quickly and independently. Ultimately, microinfrastructure is a direct response to the limitations of traditional monolithic infrastructures, offering greater responsiveness to change and an increased ability to scale in line with market demands.
"Infrastructure should be as flexible and lightweight as the services it supports."🛠️ - Pawel Piwosz
Internal development platforms and Kubernetes operators
Internal development platforms (IDPs) have become essential for simplifying developers' work and improving their productivity. George Hantzaras and Dan McKean from MongoDB highlighted the importance of Kubernetes operators in this transformation. These operators offer more efficient management of complex applications, enabling standardized configurations and reducing the cognitive load on development teams.
The operatorsKubernetes facilitate the creation of robust platforms capable of supporting a multitude of services while maintaining the flexibility necessary for systems to function properly. They automate routine operational tasks, such as application scaling, update management, and service health monitoring, allowing developers to focus on writing code rather than repetitive administrative tasks.
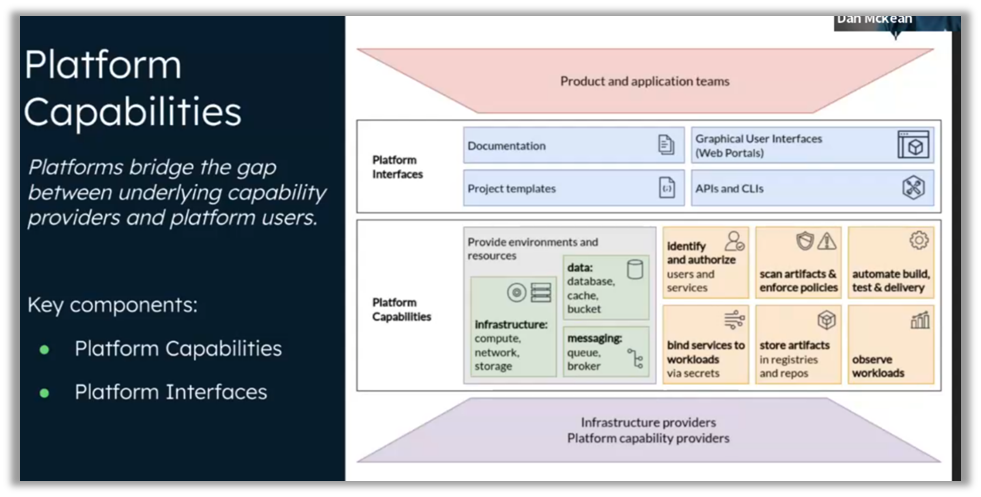
By combining these operators with GitOps solutions, companies can also leverage a declarative management model, ensuring consistency and reproducibility of deployments. ArgoCD, for example, allows you to manage the state of infrastructure and applications via configurations stored in Git, ensuring clear version control and making it easy to revert to previous states in case of problems. This not only reduces human error, but also improves transparency and collaboration between teams.
The use of Kubernetes operators also promotes the scalability of the IDP, as each operator can be specifically designed to meet the needs of different services or environments. This allows for fine-grained customization and optimized resource management, ensuring that the infrastructure remains agile and ready to adapt to rapidly changing business requirements.
"Kubernetes operators are the key to transforming Kubernetes into a true platform of platforms."🔧 - George Hantzaras
Platform engineering: lessons learned
Geert van der Cruijsen from Xebia shared his experience on common mistakes that often occur when setting up development platforms. Platform engineering can be a powerful source of efficiency, but only if the usual pitfalls are avoided. Among the most frequent mistakes are failing to take developers' needs into account, putting together ill-suited teams, and implementing a platform that is imposed on users rather than designed for them.

One of the major mistakes is treating the platform as a technical infrastructure without considering the user experience of developers. An effective platform must be thought of as a product, with developers as customers. This means constantly gathering feedback, refining features, and ensuring that the platform aligns with the evolving needs of teams. Geert van der Cruijsen emphasizes the importance of not falling into the trap of "build it and they will come": even a technically advanced platform will only be adopted if it brings real added value to users' daily lives.
In addition, the composition of the teams responsible for platform development and maintenance is crucial. Renaming an existing DevOps or Cloud Engineering team to "Platform Team" without adjusting its mission and skills does not work. A platform team must be structured to focus on creating products for development teams, facilitating their work without being directly involved in day-to-day operations.

Imposing a platform, rather than allowing it to be adopted naturally, is also a common mistake. Developers should be encouraged to use the platform, not forced. This involves creating high perceived value, eliminating friction, and implementing solutions that address the real problems encountered by developers. Otherwise, parallel initiatives and "Shadow IT" systems will emerge, rendering the official platform ineffective.

Finally, it is essential to measure ROI and analyze bottlenecks. The success of a platform is not only measured by its implementation, but by the impact it has on developer productivity, delivery speed, and the quality of the software produced.
This involves using metrics such as cycle time, adoption rate, and developer satisfaction to understand what is working well and what needs adjustment.
"A platform that does not meet the real needs of its users becomes an obstacle rather than an accelerator."🚧 - Geert van der Cruijsen
Towards antifragile platforms
Manuel Pais, author of Team Topologies, discussed the idea of an antifragile platform—a platform that not only survives crises, but improves through them. To make a platform antifragile, it must be designed in such a way that it can adapt and strengthen itself in the face of economic and organizational uncertainties. This means constantly demonstrating its value to users, not only internally but also across the entire organization.
The pillars of such a platform include internal and external trust, as well as sharing successes. Manuel Pais emphasizes the importance of measuring not only platform adoption, but also user satisfaction and the reliability of the services provided.
Creating an anti-fragile platform begins with establishing a culture of collaboration and transparent communication. Teams must be encouraged to report problems, experiment with solutions, and learn from mistakes, so that potential failures can be turned into opportunities for improvement. By cultivating this ability to leverage disruption, platforms become not only resilient, but also capable of growing stronger in the face of challenges.
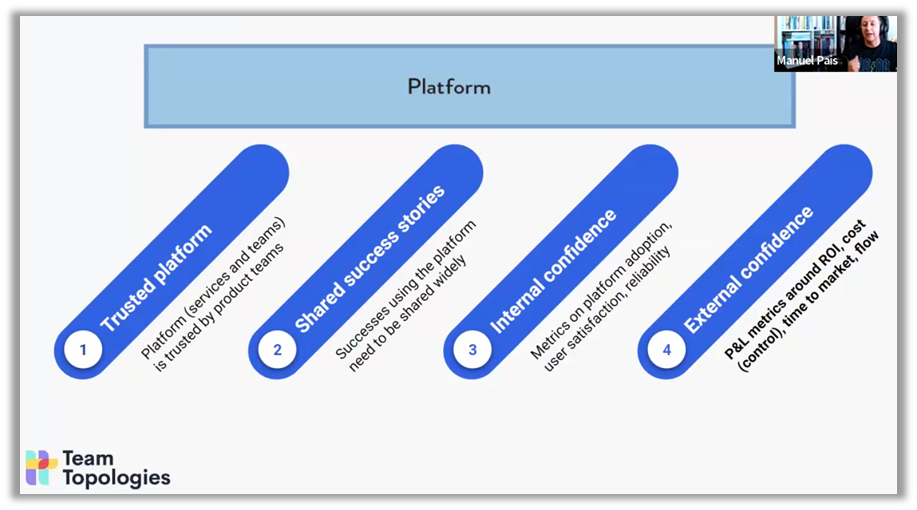
Another key aspect is the ability to iterate quickly and evolve. This requires the use of clear metrics to evaluate performance, such as reliability, adoption, and user satisfaction. These indicators enable informed decisions to be made in order to adjust features and respond to the changing needs of development teams. Manuel Pais also recommends widely sharing success stories—concrete examples where the platform has helped a team solve a problem or become more efficient—in order to build confidence in the platform's value.

In terms of governance, an anti-fragile platform must be supported by processes that promote flexibility rather than rigidity. Rather than imposing strict rules, it is about providing guidelines that allow teams to innovate while remaining aligned with the organization's overall objectives. This creates an environment where teams have the freedom to experiment while minimizing risk, thereby strengthening the robustness of the platform.
"An antifragile platform improves and thrives in the face of challenges."💪 - Manuel Pais
The evolution of software supply chains: opportunities and challenges
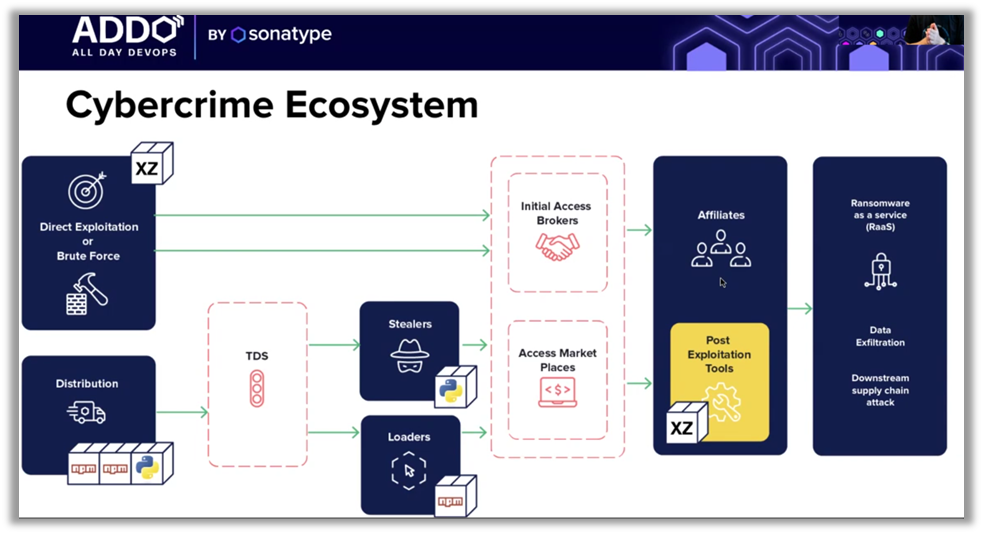
The widespread adoption of open source has radically transformed software supply chains over the past decade. The benefits are numerous: accelerated development, reduced costs, and access to a global community of innovators. However, this transformation has also increased the attack surface, exposing companies to new risks related to the security of their open source dependencies. Brian Fox, CTO of Sonatype, highlighted these challenges in his presentation, emphasizing how the growing complexity of supply chains represents a significant challenge for development and security teams.
Fox also shared the findings of Sonatype's 10th annual State of the Software Supply Chain report. The report highlights a 1,466% increase in the frequency of open source package releases over the past decade, illustrating how rapidly open source is evolving. At the same time, MTTR (mean time to repair) has increased by 800%, from 50 days to 400 days in just seven years, while the number of CVEs (Common Vulnerabilities and Exposures) has risen from 2,000 to nearly 30,000 in 25 years, an increase of nearly 1, 500%.
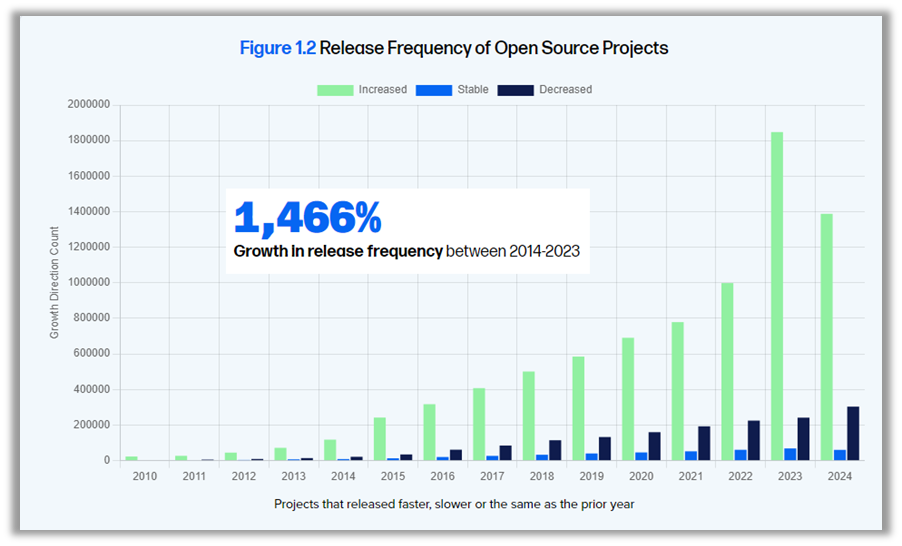
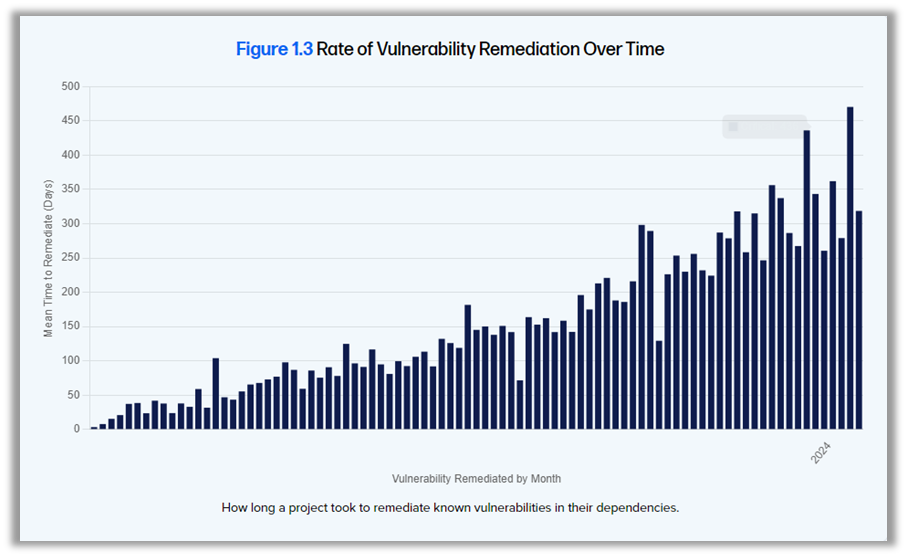
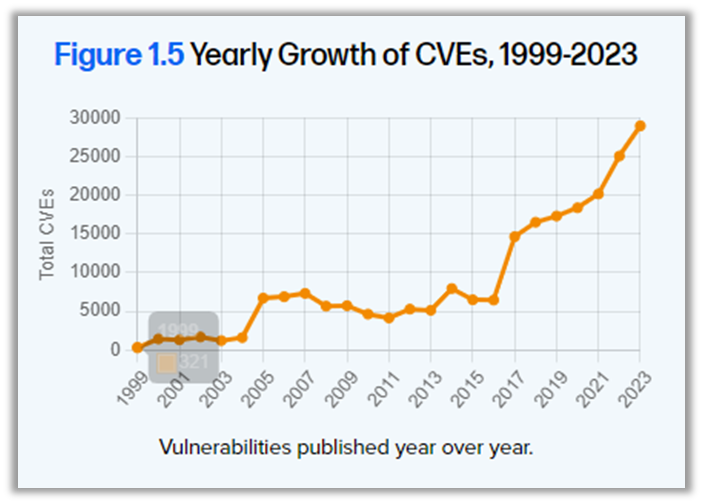
These figures clearly show the scale of the challenges companies face in terms of supply chain security. In fact, 96% of vulnerable open source projects have not been updated, creating an obvious opportunity for cyber attackers to exploit these weaknesses.
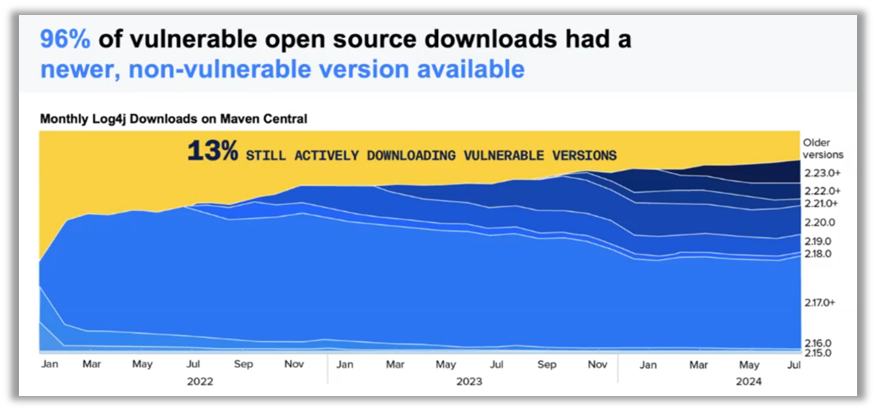
To address these challenges, Brian Fox emphasized the importance of rethinking supply chain governance. It is not just a matter of reacting to vulnerabilities after the fact, but of integrating security practices from the very beginning of the development cycle, a concept known as "shift left. "
It is necessary to promote a culture of security within development teams. This means that it is essential to empower developers and encourage them to consider security as an integral part of their daily work. This requires close collaboration between development and security teams, rigorous governance processes, and the adoption of tools that facilitate the detection and correction of vulnerabilities without disrupting workflow.
Companies must actively participate in improving the security of the components they use, rather than simply consuming open source software. By contributing to open source projects, reporting vulnerabilities, and sharing fixes, organizations not only strengthen theirown security, but also that ofthe entire ecosystem. This collaborative approach is essential to reducing the attack surface and strengthening the resilience of supply chains.
It is also crucial to implement continuous validation processes in integration and deployment pipelines (CI/CD). These processes must include regular audits of third-party components and automated verification of dependencies at each stage of the development cycle. This ensures that new software releases incorporate secure and up-to-date components, reducing the likelihood of introducing exploitable vulnerabilities.
Software composition scanner (SCA) tools can not only identify vulnerabilities but also recommend more secure versions, facilitating proactive dependency management.
In conclusion, the evolution of open source software supply chains brings significant opportunities, such as speed and collaborative innovation, but it also poses major challenges in terms of security. To reap the benefits while minimizing risks, it is essential to adopt a proactive approach to security, strengthen dependency governance, and promote a shared security culture within teams. By combining cutting-edge tools, active collaboration, and continuous vigilance, companies can ensure the resilience and reliability of their software in an increasingly complex threat landscape.
"The increasing complexity of supply chains requires proactive strategies to ensure security and resilience."🔒 - Brian Fox
Cloud-native applications and resilience
With cloud-native architectures, scalability and flexibility become inherent features, but resilience remains a major challenge. Ricardo Castro from Blip/FanDuel presented various strategies for designing applications that can withstand failures. These strategies include Blue/Green deployments, canary deployments, and the use of Dark Launches to minimize risks during production rollouts.
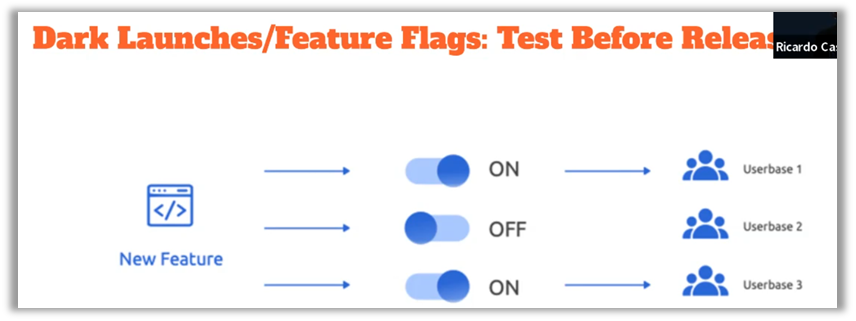
Blue/Green deployments allow two parallel environments to be maintained, ensuring a smooth transition during updates. This reduces service interruptions and makes it easier to roll back in case of problems. Canary deployments offer a gradual approach, rolling out new versions to a subset of users in order to identify potential issues before a widespread production release. Dark launches allow new features to be tested in production without exposing them directly to users, making it possible to collect real data while limiting risks.
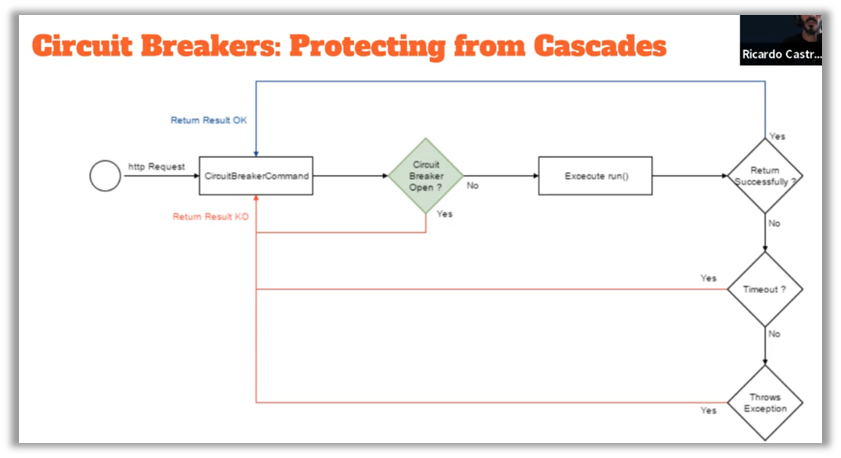
Runtime resilience patterns, such as Circuit Breakers and Bulkheads, are also crucial for ensuring application robustness. Circuit Breakers act as circuit breakers by temporarily disabling failing services, thereby preventing errors from propagating throughout the system. Bulkheads, inspired by ship compartments, isolate different parts of the system to limit the impact of failures on other components. These practices are essential to prevent an isolated failure from turning into a complete system failure.
"Building resilient cloud-native applications requires a combination of smart deployment strategies and tailored protection mechanisms."☁️⚡ - Ricardo Castro
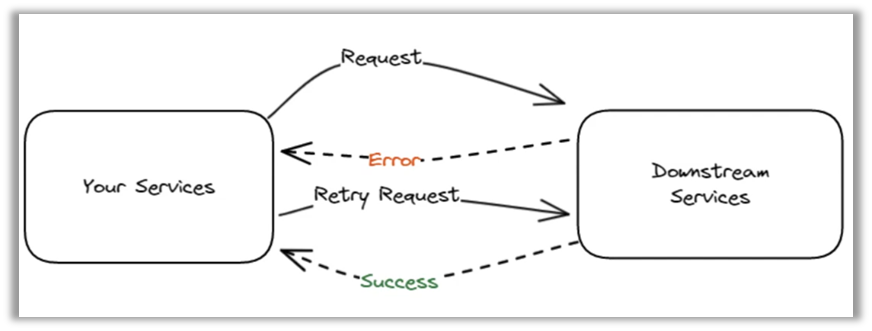
Another key strategy is the use of timeouts and retries, which allow intermittent failures to be managed by limiting the wait time for a response and retrying failed operations. This helps to avoid prolonged blockages that can adversely affect overall performance. In addition, rate limiting is an important technique for controlling the number of requests sent to a service, thereby preventing overload that could degrade service quality.
Ricardo Castro also emphasized the importance of observability in cloud-native architectures. To build resilient systems, it is essential to have complete visibility into the status of services, using monitoring, logging, and distributed tracing tools. These tools not only enable rapid detection of problems, but also identify their source and implement effective corrective actions.
The resilience of cloud-native applications therefore relies on a combination of intelligent deployment strategies, runtime protection mechanisms, and increased observability. When properly integrated, these elements ensure service continuity and a high-quality user experience, even in the face of unexpected failures.
Building a resilient future
Platform resilience and open source security are strategic imperatives for modern businesses. In an environment where threats are becoming increasingly sophisticated, a proactive approach is essential. This requires continuous monitoring, innovation in security, and close collaboration with the open source community, all of which are levers for addressing current and future challenges. As Brian Fox has said, proactive security should be seen as a strategic investment rather than a simple cost, because it enables the construction of systems that can not only withstand crises, but also thrive as a result of them.
Resilience is not limited to protection against threats: it also involves the ability to learn and continuously improve in the face of incidents. This philosophy is based on integrating best security practices throughout the development cycle, as well as implementing processes that enable a rapid and targeted response to attacks. The use of observability, monitoring, and real-time analytics tools is essential to ensure complete visibility into the state of systems, quickly identify failures, and make corrections before they become critical.
By ensuring complete visibility into operations and components, organizations can identify not only visible incidents, but also underlying weaknesses that could make them vulnerable to future attacks. Companies must also leverage AI-assisted automation to enable rapid response, efficiently allocate the resources needed to resolve incidents, and minimize the impact on operations that have little added value for manual human action.
Furthermore, collaboration with the open source community plays a vital role in building this resilience. By sharing information about new threats and actively participating in the improvement of open source tools, companies contribute to the collective security of the ecosystem. This collaboration fosters a virtuous circle: each individual contribution not only strengthens the security of the contributing organization, but also that of the entire community. This allows for the pooling of knowledge and solutions, which is particularly crucial in the face of global threats.
Proactive security is not a cost, it is an investment in building antifragile systems that thrive in the face of adversity. 🔐💡 - Brian Fox
It is time for technology leaders to ask themselves whether their current strategies are up to this requirement for resilience, or whether there is still room for improvement. 💭
For those who wish to explore the topics covered at All Days DevOps 2024 in greater depth, recorded sessions are available on demand, allowing you to revisit the experts' presentations and gain a better understanding of the issues and solutions discussed. You can access the videos via the official website: All Day DevOps.
